
Screaming Frog ist eines der bekanntesten SEO Tools überhaupt. Kein Wunder – denn man kann damit fantastische OnPage-Analysen machen. Das Tool crawlt eine beliebige Seite und sammelt dabei Informationen über die interne Linkstruktur, ausgehende Links, Überschriften, Meta-Angaben und vieles mehr.
 Das SEO OnPage Tool Screaming Frog SEO Spider wurde von der Screaming Frog Ltd. entwickelt und steht in einer kostenfreien Version zur Verfügung, die einfach heruntergeladen und auf dem PC installiert werden kann. Als Desktopanwendung ist der Screaming Frog sowohl für Windows- als auch für Mac-User verfügbar. Die vom Frosch gecrawlten SEO-Daten lassen sich sortieren, filtern und in Excel exportieren. Eine kostenlose Version erlaubt das Crawlen von 500 URLs – möchte man eine größere Seite crawlen, muss eine Lizenz erworben werden, die für 99 Britische Pfund im Jahr zu haben ist. Wir haben die kostenpflichtige Version 2,21 für euch getestet. Wie das Programm aufgebaut ist, welche Funktionen es gibt und welche Daten der Screaming Frog genau liefert, wollen wir euch im Folgenden erklären. Außerdem zeigen wir euch, wie ihr die Daten aus dem Screaming Frog kinderleicht in Excel exportieren und dort weiterverarbeiten und aufbereiten könnt.
Das SEO OnPage Tool Screaming Frog SEO Spider wurde von der Screaming Frog Ltd. entwickelt und steht in einer kostenfreien Version zur Verfügung, die einfach heruntergeladen und auf dem PC installiert werden kann. Als Desktopanwendung ist der Screaming Frog sowohl für Windows- als auch für Mac-User verfügbar. Die vom Frosch gecrawlten SEO-Daten lassen sich sortieren, filtern und in Excel exportieren. Eine kostenlose Version erlaubt das Crawlen von 500 URLs – möchte man eine größere Seite crawlen, muss eine Lizenz erworben werden, die für 99 Britische Pfund im Jahr zu haben ist. Wir haben die kostenpflichtige Version 2,21 für euch getestet. Wie das Programm aufgebaut ist, welche Funktionen es gibt und welche Daten der Screaming Frog genau liefert, wollen wir euch im Folgenden erklären. Außerdem zeigen wir euch, wie ihr die Daten aus dem Screaming Frog kinderleicht in Excel exportieren und dort weiterverarbeiten und aufbereiten könnt.
Grundlegende Einstellungen im Screaming Frog vornehmen
Crawling und Daten
Export der Daten
Auswertung mit Excel
Fazit
Grundlegende Einstellungen im Screaming Frog vornehmen
Grundsätzlich könnt ihr gleich loslegen, indem ihr einfach die zu crawlende URL in den URL-Schlitz eingebt. Wenn ihr aber eine lizensierte Version des Tools besitzt, könnt ihr unter dem Menüpunkt „Configuration“ die Default-Einstellungen abändern und damit den Crawl-Vorgang individuell für eure Seite einstellen. Hier gehen wir kurz auf die grundlegenden Punkte des sogenannten Top-Level-Menüs ein:

File
Unter dem Menüpunkt „File“ ist es möglich, den aktuellen Crawl zu speichern, einen der letzten Crawls zu öffnen oder zu wiederholen und die aktuellen Crawl-Einstellungen als Default-Einstellungen festzulegen bzw. die Default-Einstellungen zurückzusetzen.
Configuration
Über den Punkt „Configuration“ könnt ihr verschiedene Einstellungen für den Crawl vornehmen:

Spider
Unter Spider könnt ihr festlegen, was der Screaming Frog alles crawlen soll. Soll er Bilder crawlen? Soll er internen oder externen nofollow-Links folgen? Oder soll er die robots.txt ignorieren? Hier könnt ihr individuell festhalten, was ihr analysiert haben möchtet. Auch die maximale Anzahl an gecrawlten Seiten oder die maximale Crawl-Tiefe können hier definiert werden.

URL Rewriting
Hier gibt es die Möglichkeit, gecrawlte URLs umzuschreiben. Nützlich ist das beispielsweise, um Session IDs oder andere Parameter aus den URLs zu entfernen. Das kann man unter dem Tab „Remove Parameters“ tun. Unter dem Tab „Options“ gibt es die Möglichkeit, durch das Setzen eines Häkchens alle URLs in URLs mit ausschließlich kleinen Buchstaben zu konvertieren. Es ist sogar möglich, unter dem URL-Rewriting-Menüpunkt die TLD einer Seite durch eine andere TLD zu ersetzen. So könnte SEO-Trainee.de zu SEO-Trainee.com werden.
Include
Bei großen Websites bietet es sich an, diese ordnerweise zu crawlen. Sonst kann es schon mal vorkommen, dass sich der Screaming Frog bei großen Seiten komplett aufhängt. Gebt ihr unter diesem Menüpunkt einen Verzeichnispfad ein, wird ausschließlich dieses Verzeichnis gecrawlt. Screaming Frog arbeitet hier auch mit Regular Expressions. Gebt ihr zum Beispiel *wochenrueckblick* als Regex ein, werden alle Seiten, die das Wort Wochenrückblick enthalten, gecrawlt.
Exclude
Diese Funktion bildet das Gegenstück zum Include Feature. Ihr könnt sowohl einzelne Seiten vom Crawl ausschließen als auch per Regular Expression ordnerweise vorgehen.
Speed
Unter dem Punkt „Speed“ könnt ihr festlegen, wie schnell der Screaming Frog maximal crawlen soll, d.h. ihr könnt angeben, wie viele URLs pro Sekunde maximal ausgelesen werden sollen. Das kann sinnvoll sein, um eine Überlastung des Servers zu verhindern.

User Agent
Ob ihr euch als Googlebot tarnen möchtet oder als Screaming Frog SEO Spider crawlt – der User Agent ist eine wichtige Auswahlmöglichkeit. Wir empfehlen euch als Googlebot die Seite zu crawlen, denn so sieht man die Seite quasi durch die Augen von Google. Möglicherweise wird die Seite nicht allen Bots identisch angezeigt. Zur Auswahl stehen verschiedene Bots der bekannten Suchmaschinen sowie der Screaming Frog selbst. Je nachdem, was ihr hier auswählt, wird der Crawl unterschiedlich im Webanalyse-Programm der Seite (z.B. Google Analytics) getrackt bzw. erfasst.

Custom
Hinter „Custom“ verbirgt sich eine praktische Funktion: Hier könnt ihr individuelle Filter setzen, die während des Crawls berücksichtigt werden sollen. Beispiel: Ihr wollt wissen, auf welchen URLs einer Domain das Author-Tag eingebunden ist. Dann einfach rel=“author“ eingeben und schon werden alle URLs gefiltert, die das Tag beinhalten. Das Ganze funktioniert übrigens auch anders herum: Genauso könnt ihr filtern, welche URLs ein bestimmtes Tag nicht beinhalten.

Proxy
Unter „Proxy“ kann der User Proxy Server eingegeben werden.
Mode
Unter „Mode“ habt ihr die Auswahlmöglichkeit zwischen zwei Crawl-Modi. Per Default ist der Modus „Spider“ ausgewählt, bei dem ihr einfach die zu crawlende URL eingebt und schon legt der Screaming Frog los. Der zweite Modus ist der Listenmodus. Hier könnt ihr eine Liste mit allen zu crawlenden URLs im .txt-, .csv-, .xml- oder unicode text-Format hochladen. Damit das Tool die Seiten crawlen kann, müssen die URLs in der Liste als Hyperlinks (also mit http://) angegeben werden.
Advanced Exports
Unter „Advanced Exports“ ist es möglich, bestimmte Daten aus dem Screaming Frog in Excel zu exportieren. Darauf werden wir unter dem Punkt „Export der Daten“ genauer eingehen.
Reports
Unter „Reports“ ist es möglich, mittels eines Klicks einen Überblick über den Crawl herunterzuladen bzw. einen Report zu Redirect-Verkettungen.
Licence
Hinter „Licence“ verbirgt sich ein direkter Link zur kostenpflichtigen Version des Frogs. Wenn ihr einen Lizenzschlüssel für den Screaming Frog erworben habt, muss er unter diesem Menüpunkt eingegeben werden.
Help
Hinter „Help“ verbergen sich – wie der Name schon sagt – hilfreiche Funktionen zur Unterstützung wie ein Benutzer-Guide, der FAQ-Bereich und der Support-Bereich.
Crawling und Daten
Um eine Domain zu crawlen, wird einfach die URL in den dafür vorgesehenen Schlitz eingegeben und auf Start geklickt.
![]()
Während des Crawls könnt ihr ganz unten rechts sehen, wie viele URLs schon gecrawlt wurden und wie viele noch gecrawlt werden müssen (absolut und prozentual). Auch die durchschnittliche und die aktuelle Crawl-Geschwindigkeit könnt ihr unten in der Fußzeile sehen. Wenn ihr nur eine kleine Seite wie SEO-Trainee.de crawlt, geht das übrigens innerhalb von zehn Minuten.
Tipps, um auch große Seiten zu crawlen
Der Screaming Frog ist kein besonders schneller Crawler und das Crawlen von sehr großen Seiten kann zum Problem werden, weil es lange dauert oder aber der Crawler sich komplett aufhängt. Der Crawler vom Screaming Frog arbeitet standardmäßig mit 512 RAM, sodass er 10.000-100.000 URLs crawlen kann. Für den Fall, dass eure Seite sehr groß ist, haben wir drei Tipps für euch:
- Ihr crawlt eure Seite ordnerweise (Über den Menüpunkt „Configuration“ im Top-Level-Menü über die Funktion „Include“)
- Ihr weist dem Crawler mehr Arbeitsspeicher (RAM) zu. Wir ihr dabei vorgeht, lest ihr hier.
- Ihr lasst den Spider über eine Cloud-Lösung laufen (Pimp your Frog!). Eine genaue Anleitung, wie ihr das Tool auf Amazons EC2 Cloud zum Laufen bekommt, findet ihr auf dem artaxo-Blog.
Ist der Crawl abgeschlossen, bekommt ihr alle Crawl-Daten auf der Benutzeroberfläche des Tools angezeigt. Ihr könnt die Daten nun bereits im Tool filtern und sortieren. Auch hier wollen wir die einzelnen Datenbereiche, die ihr über die User Interface aufrufen könnt, einmal durchgehen. In der Ansicht des Screaming Frogs gibt es ein oberes und ein unteres Anzeigefenster der Daten. Gehen wir als erstes die Tabs aus dem oberen, großen Fenster durch:
Internal
Unter dem Tab „Internal“ findet ihr alle Daten zusammengefasst, ausgenommen sind die Daten aus den Tabs „External“ und „Custom“. Hier findet ihr also alles Wichtige in der Übersicht.
")
Hier sind alle Daten im Einzelnen kurz erklärt:
- Address: zeigt die gecrawlte URL an
- Content: zeigt den Content Typ an (z. B. Text oder jpg)
- Status Code: zeigt den HTTP-Statuscode an
- Status: zeigt den HTTP Header Response an
- Title 1: zeigt den Title der Seite an
- Title 1 Length: zeigt die Zeichenanzahl des Titles an
- Meta Description 1: zeigt die Meta Description an
- Meta Description Length 1: zeigt die Zeichenanzahl der Meta Description an
- Meta Keyword 1: zeigt die Meta Keywords an
- Meta Keywords Length: zeigt die Zeichenanzahl der Meta Keywords an
- h1 – 1: zeigt die erste H1-Überschrift an
- h1 – Len-1: zeigt die Zeichenanzahl der H1-Überschrift an
- h2 – 1: zeigt die erste H2-Überschrift an
- h2 – Len-1: zeigt die Zeichenanzahl der H2-Überschrift an
- Meta Data 1: zeigt die robots-Metadaten an
- Meta Refresh 1: zeigt die Meta-Refresh-Daten an
- Canonical: zeigt die Canonical Tags an
- Size: zeigt die Seitengröße in bytes an
- Word Count: zeigt die Wortanzahl auf der Seite an
- Level: zeigt an, wie viele Klicks die Seite von der Startseite entfernt ist
- Inlinks: zeigt an, wie viele interne Links auf die Seite zeigen
- Outlinks: zeigt an, wie viele interne Links von der Seite ausgehen
- External Outlinks: zeigt an, wie viele externe Links von der Seite ausgehen
- Hash: zeigt bei Unique Content für jede Seite einen individuellen Hash Value an; bei identischen Inhalten bekommen mehrere Seiten denselben Hash Value zugeteilt
- Title 2, meta description 2, h1-2, h2-2 etc: zeigen weitere Daten des Crawls an; der Screaming Frog nimmt die ersten zwei Elemente aus dem Quellcode hier auf
Über den Tab „Internal“ könnt ihr die wichtigen Daten schön gesammelt und alle auf einmal exportieren. Über die Tabs „Response Codes“, „URI“, „Page Titles“, „Meta Description“, „Meta Keywords“, „H1“, „H2“, „Images“ und „Directives“ könnt ihr euch ausgewählte Daten einzeln anzeigen lassen. Zudem gibt es zwei weitere Tabs:
External
Wenn ihr unter Configuration à Spider das Häkchen bei „Check External Links“ gesetzt habt, findet ihr unter diesem Punkt die Informationen zu externen URIs zusammengefasst.
Custom
Die Customized Daten erhält man nur, wenn man die entsprechenden Filtereinstellungen unter „Configuration“, „Custom“ vorgenommen hat.
Daten auf Seitenenebene
Wenn man in der Datenübersicht des oberen Anzeigefensters eine URL auswählt, kann man sich über die Tabs im unteren Anzeigefenster („URL Info“, „In Links“, „Out Links“ und „Image Info“) die Informationen auf Seitenebene anzeigen lassen.
Export der Daten
Ihr könnt euch die Daten bequem in Excel exportieren, um daraus tiefergehende Auswertungen zu machen. Es gibt mehrere Exportmöglichkeiten:
Der normale Export
Grundsätzlich ist der Export aus allen Daten der einzelnen Tabs möglich. Dazu geht ihr auf den gewünschten Tab und klickt auf der linken oberen Ecke auf „Export“. Ihr exportiert also immer die Daten, die euch gerade im Fenster angezeigt werden.
Der Advanced Export
Die Möglichkeit zum Advanced Export findet ihr im Top-Level-Menü. Hier könnt ihr Daten zu einem bestimmten Bereich gebündelt exportieren. Wählt im Menü aus, ob euch beispielsweise alle Links, die auf 404-Seiten führen, interessieren, oder alle Bilder, bei denen das Alt-Tag nicht gesetzt wurde.
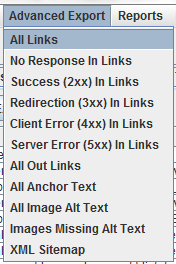
Auswertung mit Excel
Die .csv-Datei ins .xlsx-Format bringen
Habt ihr euch für eine Exportart entschieden, wählt ihr einen Speicherort aus und öffnet dann Excel mit einem leeren Tabellenblatt. Wir wollen jetzt die Daten ins .xlsx-Format importieren. Geht dazu in eurem leeren Excel-Tabellenblatt auf „Daten“ und wählt „aus Text“ aus. Hier wählt ihr nun eure abgelegte Datei aus und bringt den ungeordneten Text ins .xlsx-Format. Schaut euch das Video an, um zu sehen, wie es genau geht. Zum Schluss solltet ihr eine schöne übersichtliche Tabelle haben.

Sie sehen gerade einen Platzhalterinhalt von Youtube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
In dieser Tabelle könnt ihr jetzt weitere Auswertungen vornehmen. Nehmen wir an, ihr habt über den normalen Export des oberen Anzeigefensters alle Daten des Tabs „Internal“ exportiert. So ist es zum Beispiel in einem ersten einfachen Schritt möglich, über „Bedingte Formatierung“ diejenigen Title zu markieren, die länger als 70 Zeichen sind. Dazu müsst ihr im Hauptmenü auf „Bedingte Formatierung“ klicken und unter „Neue Regel“ eine entsprechende Regel erstellen. In diesem Fall wählen wir „Nur Zellen formatieren, die enthalten“ und geben an, dass nur Zellen mit einem Zellwert größer als 70 farblich hinterlegt werden sollen. So seht ihr auf den ersten Blick, welche Title zu lang sind und von Google für die Darstellung in den Suchergebnissen abgeschnitten werden.
Die Verlinkung mit Pivot Tabellen analysieren
Welche Seiten sind schwach, da sie wenige oder gar keine internen Links enthalten? Welche Seiten sind besonders stark intern verlinkt? Welche Seiten sind Hub Pages, weil von ihnen viele Links auf andere Seiten gehen? Insbesondere bei großen Seiten macht es Sinn, diese Fragestellungen mithilfe von Pivot-Tabellen zu beantworten. Wählt dazu den Advanced Export „All Anchor Text“ aus. Vergesst nicht, eure Daten anschließend in Excel spaltenweise darzustellen. Wenn ihr ausschließlich die interne Verlinkung ansehen wollt, sortiert die Spalte „Destination“ mit einer erweiterten Markierung alphabetisch. Nun könnt ihr Links, die auf externe Seiten verweisen, einfach aus der Tabelle löschen.
Als erstes wollen wir uns anschaulich darstellen lassen, welche Seiten besonders gut beziehungsweise besonders schlecht verlinkt sind und welche Anchor-Texte wie häufig für die Verlinkung genutzt wurden:
- Geht in eurem Excel-Tabellenblatt auf Einfügen –> Pivot Tabelle
- Wählt nun erst „Destination“ und anschließend „Anchor-Text“ aus und ordnet sie unter Zeile ein
- Wählt „Destination“ aus und ordnet es diesmal unter „Wert“ an
Sie sehen gerade einen Platzhalterinhalt von Youtube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Fertig! Euch wird nun in der Pivot-Tabelle angezeigt, welche URLs wie viele eingehende Links erhalten und welcher Anchor-Text wie häufig für diese URL benutzt wurde. Hier ein kleiner Auszug aus unserer Pivot-Tabelle. Unsere Startseite erhält also insgesamt 2045 Links. Über 800 Mal ist die Startseite mit dem Anchor SEO Trainee verlinkt.

Als nächstes interessiert uns, welche Seiten als sogenannte Hub Pages fungieren. Hub Pages haben eine navigierende Funktion, da von ihnen viele Links auf andere Seiten gehen.
- Geht in eurem Excel-Tabellenblatt auf Einfügen –> Pivot Tabelle
- Wählt nun erst „Source“ und danach „Anchor-Text“ aus und ordnet es unter Zeile ein
- Wählt „Source“ ein zweites Mal aus und ordnet es diesmal unter „Wert“ an
In dieser Pivot-Tabelle seht ihr nun, von welchen Seiten wieviele Links mit welchen Linktexten ausgehen.
Diese beiden Tabellen helfen bei folgenden Fragestellungen:
- Sind die Zielseiten mit dem richtigen Anchor-Texten verlinkt?
- Gibt es Seiten, die intern zu wenig verlinkt werden, obwohl sie wichtige Inhalte bereitstellen?
Wichtig ist so eine Analyse vor einem Relaunch oder der Umstrukturierung eurer Website. Doch auch um generell auf dem Laufenden über die Linkstruktur zu bleiben, empfiehlt es sich, diese Auswertung regelmäßig zu wiederholen. Da der Screaming Frog auch die Analyse von fremden Seiten erlaubt, kann man auch gut schauen, welche Keywords von der Konkurrenz durch die interne Verlinkung gestärkt werden und somit von besonderer Relevanz sind.
Weitere Anwendungsbeispiele
Die oben beschriebenen Auswertungen sollen lediglich als Beispiel dienen – mit dem Screaming Frog (und Excel) könnt ihr noch einiges mehr an Datenanalysen vornehmen.
So liefert der Frog z.B. nicht nur Informationen darüber, welche Seiten einen 404-Fehlercode ausspielen, sondern gibt auch an, welche anderen Seiten intern auf diese 404-Seiten verlinken. So kann man kinderleicht fehlerhafte interne Links identifizieren und diese entsprechend korrigieren. Gleiches gilt natürlich auch für URLs mit dem Statuscode 301 oder 302. Handlungsempfehlung: Anstatt intern auf eine Seite mit Weiterleitung zu verlinken, sollte lieber direkt diejenige URL verlinkt werden, auf die die weitergeleiteten URLs verweisen.
Unter „Überschriften“ und „Wortanzahl“ findet ihr auf einen Blick wichtige Informationen darüber, wie einzelne Seiten in Bezug auf textuellen Content aufgestellt sind. Sind die Überschriften aussagekräftig? Sind die Texte lang genug, sodass sie von Google auch gewertet werden?
Und auch über die Informationsarchitektur bietet der Screaming Frog Aufschluss: Unter „Level“ könnt ihr sehen, wie viele Klicks jede URL von der Startseite entfernt ist. Diese Werte in Excel einfach sortieren oder über eine bedingte Formatierung die Werte größer als Fünf markieren – und schon seht ihr, wie viele und welche Unterseiten zu weit von der Startseite entfernt liegen und unter Umständen vom Crawler gar nicht erreicht werden.
Ihr seht: Was ihr aus den Daten des Screaming Frogs herausholt, liegt ganz bei euch! 😉
Fazit
 Grundsätzlich bietet der Frosch umfassende Daten für die OnPage-Analyse einer Seite. Ob Meta-Angaben wie Title und Description, 404-Fehlerseiten und interne Verlinkungen auf diese oder interner Duplicate Content – der Screaming Frog liefert die relevanten Informationen, um derartige Fehlerquellen aufzuspüren. Die Benutzeroberfläche hat zwar nicht das allerschönste Design, ist aber leicht verständlich und intuitiv bedienbar. Zudem besteht die tolle Möglichkeit, über „Customs“ beliebige Filter zu setzen, mittels derer die Seite auf ganz individuelle Aspekte hin analysiert werden kann. Kleines Manko: Große Seiten zwingen den Frog (und auch die Excel-Tabelle mit den exportierten Daten) manchmal in die Knie. Nichtsdestotrotz ist er ein nützliches Tool zur Aufdeckung von OnPage-Potenzialen, das jeder SEO einmal ausprobieren sollte!
Grundsätzlich bietet der Frosch umfassende Daten für die OnPage-Analyse einer Seite. Ob Meta-Angaben wie Title und Description, 404-Fehlerseiten und interne Verlinkungen auf diese oder interner Duplicate Content – der Screaming Frog liefert die relevanten Informationen, um derartige Fehlerquellen aufzuspüren. Die Benutzeroberfläche hat zwar nicht das allerschönste Design, ist aber leicht verständlich und intuitiv bedienbar. Zudem besteht die tolle Möglichkeit, über „Customs“ beliebige Filter zu setzen, mittels derer die Seite auf ganz individuelle Aspekte hin analysiert werden kann. Kleines Manko: Große Seiten zwingen den Frog (und auch die Excel-Tabelle mit den exportierten Daten) manchmal in die Knie. Nichtsdestotrotz ist er ein nützliches Tool zur Aufdeckung von OnPage-Potenzialen, das jeder SEO einmal ausprobieren sollte!
Noch eine schöne Restwoche wünschen
Amke und Gesa, die SEO Trainees




19 Antworten
Sehr schöner Beitrag zum Screamingfrog – bietet mithin das beste Preis-Leistungsverhältnis sämtlicher SEO Tools, wobei auch Strucr mit der kostenlosen Version extrem viel Funktionen & Möglichkeiten präsentiert!
Als Mac Nutzer habe ich hier im Appstore seospyder gefunden. mobiliodevelopment.com/seospyder. Man findet bei Google wenig darüber. Der Autor geht auf die Unterschiede zum Screaming Frog ein. Was ist davon zu halten?
Danke für den Beitrag, ich werde das tool gleich ausprobieren und selbst auf herz und nieren prüfen.
Lg
Matthias
Sehr schön. Endlich kein manuelles checken der Seiten mehr nötig. Dankesehr für den Artikel zu dem wirklich hilfreichen Tool.
Viele Grüße
Rudi
Moin,
Habe das Tool mal getestet und bin recht angetan, aber: Für ein eher kleines Webprojekt ist es einfach recht über dimensionier und gibt einfach zu viele Baustellen bekannt, um „mal schnell“ die Low Hanging Fruits zu ernten.
Moin Atilla,
danke für deinen Kommentar. Du hast Recht – der Screaming Frog ist in seinen Analysen recht detailliert und liefert viele Hinweise auf Optimierungspotenziale. Nichtsdestotrotz denke ich, dass gerade die kostenfreie Version auch für kleine Webprojekte geeignet ist. Die verschiedenen Baustellen muss man dann selbst priorisieren – was natürlich für SEO-Einsteiger mitunter schwierig sein kann. Aber so ein Gesamtüberblick über die eigene Seite kann nie schaden, denke ich.
Beste Grüße,
Amke
Super Tool, danke für die Empfehlung.
🙂
Jan Haarausfall 🙂
Netter Versuch!
Sieht mir nach einem sehr praktischen Tool aus, danke für das ausführliche Review. Werds gleich mal ausprobieren!
Happy Frogging! 🙂
Das klingt nach einem echt tollen Tool. Gibt es irgendeine Möglichkeit, das unter Linux zum Laufen zu kriegen?
Hey Yuliyah ,
leider nicht direkt, sondern ur in einer virtuellen Maschine.
Mir scheint dieses Tool allerdings schon fast etwas zu umfrangreich 😉 !
Schau dir für Linux mal das an: WebSite Auditor von link-assistant.com
MfG
Frieder
Super ausführlicher und gut verständlicher Artikel zum Screaming Frog Spider. Das Problem, dass sich der SF bei großen Seiten oft aufhängt, kenn ich leider nur zu gut. Da ist der Tipp mit dem ordnerweisen Vorgehen sehr nützlich. Eventuell nutzt man bei sehr großen Seiten auch einfach Strucr.
Kleine Ergänzung; Screaming Frog steht auch für Ubuntu (Linux) zur Verfügung.
Fantastisches Tool, vielen Dank! Könnte einige Funktionen der doch nicht ganz günstigen Toolbox der großen Firma mit S ersetzen…feinfein!
Super Tool, habs direkt mal ausprobiert und bin echt begeistert.
Hi Markus,
man kann so viel mit dem Tool machen und teilweise wird der Frog noch von Vielen unterschätzt. Schön, dass dich unser Artikel inspiriert hat, den Screaming Frog auszuprobieren! 🙂
Liebe Grüße,
Gesa