Das PRG-Pattern ist eine effektive Methode zur Linkmaskierung. Dabei werden Get-, Redirect- und Post-Requests verwendet, um einen Link vor der Suchmaschine zu verbergen. Das hat vor allem für Online-Shops Vorteile, wird aber auch in anderen Fällen verwendet.
In diesem Artikel erklären wir Euch das PRG-Pattern so einfach wie möglich. Grundkenntnisse in HTML und Client-Server-Architektur sind dabei hilfreich, aber nicht notwendig.
überarbeitet von Simon Thijs am 13.04.2023
Warum Links mit PRG-Pattern maskieren?
Bei dem einen oder anderen SEO klingeln jetzt wahrscheinlich die Alarmglocken. Etwas vor Google zu „verstecken“, erinnert an Blackhat-Methoden wie dem Cloaking, bei dem der Suchmaschine andere Inhalte als dem Nutzer angezeigt werden. Bei Google ist diese Methode der Linkmaskierung allerdings bekannt – es wurden weder Bedenken geäußert noch in irgendeiner Weise gefordert, dies zu unterlassen.
Es gibt verschiedene Fälle, in denen es sinnvoll ist, Links zu maskieren. Die Gründe sind dabei meistens:
- Crawl-Budget sparen
- Duplicate Content vermeiden
- Usability verbessern
- Interne Verlinkung optimieren
1. Crawl-Budget sparen & Duplicate Content vermeiden
Die Themen Crawl-Budget und Duplicate Content sind vor allem für größere Online-Shops relevant. Denn sie haben oft sogenannte facettierte Filter-Navigationen.
Ihr könnt damit Waren nach Größen, Farben, Preisen und vielem mehr filtern. Durch die verschiedenen Filter-Kombinationen werden unzählige Parameter-URLs erzeugt. Hinter jedem Filter-Button steckt im Grunde ein interner Link. Crawler können diesen folgen und so zahlreiche gefilterte Seiten indexieren. Dies strapaziert das Crawl-Budget enorm. Außerdem unterscheiden sich die Seiteninhalte nur minimal, zum Beispiel in der Sortierung der Produkte. Es droht Duplicate Content. Damit Suchmaschinen wirklich nur indexrelevante Filter crawlen, können verschiedene Filter maskiert werden. Die Funktion der Filter wird dadurch nicht beeinträchtigt.
2. Usability verbessern
Das Post-Redirect-Get-Pattern verbessert vor allem bei Formularen die Usability. Die Methode wird vor allem bei der Eingabe von Formulardaten verwendet. Sie verhindert, dass beim Zurück-Button oder neu laden eine erneute Übersendung der Formulardaten stattfindet.
3. Interne Verlinkung: Linkjuice steuern & Themen-Siloing
Eine gute interne Linkstruktur ist extrem wichtig für die Suchmaschinenoptimierung. In unserem Fachartikel zur internen Verlinkung erfahrt ihr mehr dazu. Hier nur zwei wichtige Punkte im Zusammenhang mit Linkmaskierung:
- Google hält Seiten, die am häufigsten intern verlinkt sind, für eure wichtigsten Inhalte (meistens die Startseite). Außerdem geht die Suchmaschine davon aus, dass Content, der auf einer Seite verlinkt ist, auch etwas mit deren Thema zu tun hat. Mit einer internen Verlinkung helft ihr den Bots also, eure Seitenstruktur und Inhalte schneller zu verstehen.
- Wenn eine Website einen gewissen Mehrwert bietet, wird sie häufig von anderen verlinkt. Habt ihr also viele externe Links von Seiten mit guter Qualität, hilft das eurer Seite bei Suchmaschinen zu ranken. Ankommende externe Links vererben nämlich ein wenig vom guten (oder schlechten) Ruf der Ursprungsseite. Dieses Signal wird “Linkpower“ oder „Linkjuice“ genannt (auch wenn Google den Ausdruck nicht mag). Auf Eurer Webseite geht diese Vererbung weiter. Die Power, die Ihr durch externe Links bekommt, wird an alle interne Links auf einer Seite weitervererbt. Diese Linkpower ist natürlich begrenzt – viele Links dünnen sie aus. Je mehr auf einer Seite vorhanden sind, desto weniger Linkjuice bekommt jeder einzelne Link. Seiten, die auf Euren Domains sehr häufig verlinkt werden, erhalten typischerweise mehr Linkpower. Welche das sind, könnt ihr übrigens in der Google Search Console unter dem Menüpunkt „Interne Links“ nachsehen. Das heißt: Habt Ihr eine Seite, die viele starke externe Links hat, dann überlegt euch gut, an welche anderen internen Seiten ihr diese Power weitergeben wollt.
Nun gibt es 2 Bereiche von Webseiten, die das Erkennen von Themen-Blöcken (Siloing) und die gezielte Weitergabe von Linkjuice behindern können.
- Flyout-Navigationen: Viele Seiten haben eine Hauptnavigation, aus der bei Klick oder Mouseover wiederum viele Unterseiten und -kategorien ausklappen. Jede davon ist ein interner Link, der von Suchmaschinen gecrawlt wird. Um ein besseres Themen-Siloing zu erhalten, ist eine genauere Ausrichtung der internen Verlinkung sinnvoll. Dies geschieht, indem ihr Teile der Navigation maskiert. Beim Themen-Siloing selbst erfolgt eine Maskierung inhaltsfremder Links. Dadurch kann die Suchmaschine das tatsächliche Thema jeweiliger Bereiche genauer erfassen. Zum Beispiel wäre es sinnvoll, in einem Webshop im Segment Herren-Kleidung die Links zu Damen-Kleidung zu maskieren.
- Footer-Links: Dasselbe wie bei Flyout-Navigationen könnte auch für Footer-Links gelten. Diese wiederholen sich auf jeder Seite und sind oft nicht indexrelevant. AGB, Datenschutz, etc. müssen sogar rein rechtlich von jeder Unterseite aus direkt erreichbar sein. Ihr könntet diese Links also ebenfalls maskieren und viele tun das auch. Allerdings versteht Google inzwischen Inhalte sehr gut. Der Suchmaschine ist also klar, dass das Impressum sowie andere Links im Footer nicht eure wichtigsten Seiten sind, nur weil es die meisten internen Links abbekommt. Hier ist es also möglich, aber nicht notwendig, Links zu verstecken.
Get vs Post: Grundlegende Funktionsweise des PRG-Patterns
Wenn ihr das PRG-Pattern verwendet, geht es also in erster Linie darum, Links zu maskieren. Aber wie funktioniert die Methode genau?
PRG steht für Post-Redirect-Get. „Redirect“ kennt ihr sicherlich, denn eine Umleitung richtet ihr ein, wenn ihr eine Seite umzieht oder sich eine URL ändert. Was aber ist der Unterschied zwischen Post und Get?
Get-Request
Generell werden im HTTP-Protokoll Seiten standardmäßig durch einen Get-Request angefordert. Mit einer Get-Anfrage sagt der Client (Browser) dem Server, was er haben will, und dieser gibt es aus. Dabei werden die Eingabedaten als Parameter an die URL angehängt und so dem Server übergeben. Diesen Parameterlinks können Suchmaschinen ohne Probleme folgen.
Wollt ihr zum Beispiel Experte für Suchmaschinenoptimierung werden, dann klickt ihr auf unsere Bewerbungsseite. Damit sagt ihr dem Server von seo-trainee.de, dass ihr das Dokument „bewerbung-seo-trainee“ haben wollt. Ihr bekommt dann die Seite mit der URL https://www.seo-trainee.de/bewerbung-seo-trainee/.
Bei der internen Suchfunktion einer Seite oder wenn ihr Produkte in einem Online-Shop filtert, werden in der Regel ebenfalls Get-Anfragen geschickt. Ihr erkennt die Parameter jeweils in der Adresszeile.
Auch ein Login würde per Get funktionieren. Ihr gebt eure Anmeldedaten ein und stellt damit die Anfrage, auf euer Benutzer-Kontor geleitet zu werden. Problem: Bei einem Get-Request wären die Anmeldedaten samt Passwort in der URL sichtbar.
Außerdem können mit einer Get-Anfrage keine Dateien an einen Server übermittelt werden.
Post-Methode
Mit Post übermittelt der Client (in der Regel der Browser) Daten an den Server nicht über die URL, sondern unsichtbar innerhalb des sogenannten Request-Bodys. In diesem können weitere Daten angehängt werden. Diese Technik eignet sich daher beispielsweise, um Bilder im Internet hochzuladen. So könnt ihr auf Bewerbungsportalen wie unserem auf artaxo.com neben euren Infos auch Dokumente wie Zeugnisse mitschicken.
Ein Post-Request erzeugt keinen neuen Link. Crawler ignorieren außerdem Formulare mit Post-Methode. Das liegt daran, dass Post-Formulare standardmäßig dafür genutzt werden, individuelle Daten beim Server hochzuladen. Für den Crawler macht es keinen Sinn, dies zu tun. Dieser verarbeitet sie und gibt eine Antwort aus, wenn er erfolgreich war oder auch gescheitert ist.
In einem Online-Shop legt ihr zum Beispiel Waren in den Einkaufswagen, gebt dann eure Zahlungs- und Adressdaten ein, bevor ihr auf „Bestellen“ klickt. Ihr sendet damit Daten an den Server, er prüft sie und zeigt im Normalfall eine Seite wie „Bestellung erfolgreich“ an.
Problem: Manchmal dauert die Verarbeitung etwas und weil wir immer ungeduldig sind, aktualisieren wir die Seite vielleicht. Dann würde die Bestellung nochmal abgeschickt werden. Dasselbe würde passieren, wenn ihr nach dem Kauf auf den Zurück-Button des Browsers klickt.
Außerdem kann ein Post nicht gebookmarkt werden, weil die Infos ja nicht in der URL stehen. Würden Filter-Einstellungen in Webshops per einfachem Post passieren, könntet ihr für eure persönliche Ergebnisseite kein Lesezeichen setzen oder sie per Link mit anderen teilen.
PRG-Pattern-Link
Das PRG-Pattern vereint die Vorteile von Post & Get ohne ihre Nachteile. Bleiben wir beim Beispiel Bestell-Vorgang. Zunächst übermittelt ihr per Post bestimmte Informationen an den Server, ohne dass sie in der URL sichtbar sind.
Statt jetzt sofort die Bestellbestätigung auszugeben, schickt der Server die Info an den Client (also den Browser), dass eine Weiterleitung (Redirect) existiert und gibt die „neue“ Ziel-URL mit. Die ruft der Client jetzt wieder per Get-Anfrage beim Server ab und bekommt schließlich die Seite „Bestellbestätigung“ oder ähnliches.
Klicken Benutzer*innen jetzt auf „aktualisieren“ oder „zurück“, findet nur der Get-Request erneut statt. Es wird kein doppelter Bestellvorgang ausgelöst.
Durch Post-Redirect-Get kann der Server auch an eine Parameter-URL weiterleiten, beispielsweise an eine gefilterte Produktseite. Ihr wählt in einem Shop z. B. die Filter „Pullover“, „Herren“, „Farbe blau“, „Größe M“, „Material Baumwolle“, „Preis bis 50€“.
Jede geklickte Einstellung ist eine Datenübermittlung per Post. Erst über den Umweg der Weiterleitung gibt der Server aber die gefilterten Ergebnisse aus. Die URL dieser Ergebnisseite kann per Lesezeichen gespeichert oder als Link geteilt werden. Weil der Auslöser aber ein „Post“ ist, folgen Crawler dem Link nicht.
Technische Umsetzung des PRG-Patterns
Der Nachteil des PRG-Patterns ist definitiv seine Umsetzung. Dazu müsst ihr nämlich schon recht gute Kenntnisse in HTML, PHP, CSS und Co. haben und direkt im Quellcode arbeiten. Daher zunächst ein kleiner Crashkurs zum Thema Client-Server-Kommunikation:
Neben des klassischen Links, der im HTML durch einen Anker <a> realisiert wird, gibt es weitere Möglichkeiten, einen Nutzer auf eine Seite navigieren zu lassen. PRG-Pattern verwendet statt eines Ankers ein Formularfeld <form>.
Formulare werden auf Websites überall dort eingesetzt, wo Nutzer eine Eingabe tätigen, zum Beispiel bei einer internen Suche.
So sieht zum Beispiel das Suchfeld von seo-trainee.de im Seitenquelltext aus:

Um einen Link zu maskieren, ist es jetzt noch wichtig, dass die Anweisung des Form-Elements über einen „Post-Request“ statt wie bei unserer internen Suche mittels „Get-Request“ an den Server übermittelt wird. Das ist bei den meisten Login-Seiten der Fall.
Die Daten, die ein Nutzer dabei eingibt, werden an den Server übermittelt. Dieser prüft, ob Nutzername und Passwort richtig sind. Anschließend leitet er den User auf seine Zielseite weiter.
Was müsst ihr bei der Verwendung des PRG-Patterns beachten?
Beim PRG-Pattern wird im Gegensatz zu einem herkömmlichen Link kein Anker-Tag <a>, sondern ein Formular-Tag <form> verwendet. Deshalb solltet ihr darauf achten, auch für das klickbare Formular-Element entsprechende CSS-Anweisungen anzulegen, damit es sich optisch nicht von den anderen Links der Seite unterscheidet.
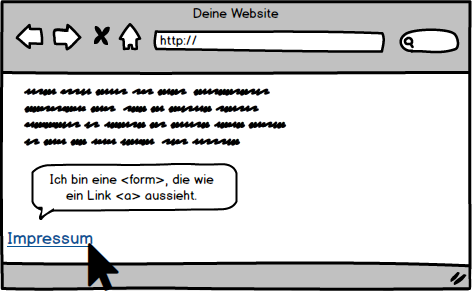
Achtet bei der Verwendung von PRG-Links darauf, dass Seiten, die indexiert werden sollen, weiterhin durch mindestens einen crawlbaren Link erreichbar bleiben. Wenn ihr beispielsweise Links im Footer maskiert, bietet es sich an, auf der Startseite auf eine PRG-Maskierung zu verzichten. Dadurch stellt ihr sicher, dass diese weiterhin gecrawlt werden können.
Außerdem solltet ihr nicht in Versuchung kommen, sämtliche externe Links über ein PRG-Pattern zu maskieren, um all den wertvollen Linkjuice für Euch zu behalten. Zu einer typischen Website gehören selbstverständlich auch externe Links. Ein natürliches Linkprofil besteht nicht nur aus eingehenden Links.
Alternativen zum PRG-Pattern
- NoFollow: Entgegen der landläufigen Meinung wird durch die Verwendung von NoFollow kein Linkjuice eingespart, sondern lediglich entwertet. Daher eignet sich diese Methode nicht zur Steuerung von Linkjuice. Ohnehin wurde die NoFollow-Kennzeichnung ursprünglich eingeführt, damit sich Seitenbetreiber von Werbelinks distanzieren und sich vor Foren-Spam schützen können. Wenn ihr interne Links mit NoFollow kennzeichnet, distanziert ihr Euch von euren eigenen Inhalten. Dies ist sicherlich kein positives Signal an die Suchmaschine.
- Robots.txt: Mittels Anweisungen in der robtos.txt. könnt ihr Seiten von Crawlings ausschließen. Die Methode spart allerdings auch keinen Linkjuice ein. Heißt: Habt ihr vier interne Links auf einer Seite, wovon einer vom Crawling ausgeschlossen ist, bekommen die anderen 3 trotzdem nur ein Viertel der Linkpower der externen Links.
- Canonical & NoIndex: Um Duplicate Content zu vermeiden, könnt ihr auch per Canonical Tag eine Seite als die Hauptseite ausweisen. Das machen viele Webshops, da sie für jede Variante (z. B. Farbe) eines Produktes eine eigene Seite haben, diese aber im Grunde alle identisch sind. Crawl Budget spart ihr damit aber nicht. Der Vorteil ist aber die sehr einfache Umsetzung.
- NoIndex: Ihr könnt doppelte Seiten auch komplett vom Index ausschließen. Dann tauchen sie aber nicht mehr in den Suchergebnissen auf. Außerdem verhindert auch diese Methode nicht, dass Seiten gecrawlt werden.
Fazit
PRG-Pattern sind sehr wirkungsvoll, um die interne Verlinkung und das Crawl Budget zu verwalten. Bei der tatsächlichen Umsetzung werden aber gewisse Grundkenntnisse in HTML, PHP, CSS und Server-Client-Kommunikation benötigt. In diesem Guide haben wir auf Code-Beispiele verzichtet und den Fokus auf SEOs gelegt, die sich das erste Mal mit dem Thema PRG-Pattern beschäftigen. Um das Prinzip besser zu verstehen, solltet ihr Euch jedoch verschiedene Codebeispiele ansehen, die zu diesem Thema bereits zu finden sind. Dabei ist es hilfreich, sich zuerst mit der Funktionsweise von HTML-Forms zu beschäftigen.
überarbeitet von Simon Thijs am 13.04.2023
Über den Gastautor:

Daniel Frent ist SEO-Consultant bei der eology GmbH in Volkach. Während seines E-Commerce-Studiums eignete er sich ein breites Wissen über SEO, SEA und Conversion-Optimierung an. Durch die Arbeit in der Agentur und die verschiedenen Kunden kommt dabei immer etwas Neues hinzu. Da er sich in der Studienvertiefung auf Conversion-Optimierung spezialisiert hat, setzt er bei seinen Projekten gerne mal die SEO-Brille ab und achtet auf eine gute Usability.




10 Antworten
Welchen Vorteil bietet das PRG-Pattern im Gegensatz zu
1. ausschließen der URLs über rel=nofollow
2. Verbieten des Crawlings der Ziel URLs über robots.txt
Hallo Alex,
vielen Dank für Dein Kommentar und das damit verbundene Interesse an SEO-Trainee. Zusammenfassend kann gesagt werden, dass das Crawl Budget auch durch die Varianten gespart werden kann, die du bereits erwähnt hast. Um gegen die Verschwendung von Link Juice am besten gegen anzugehen, eignet sich das PRG-Pattern am besten.
Viele Grüße
Janek
Zum Thema „Nofollow bei internen Links“ heist es ja sinngemäß: Verschwende nicht deine Zeit damit, dadurch irgendwie den Linkflow zu steuern zu wollen“. Aber warum sollte das bei einer anderen Methode anders sein? Und soll PRG die einzige Methode sein, einer Suchmashine „mitzuteilen“ Dass es sich nicht loht, gewisse Seiten „anzugucken“?
Wie sieht es denn mit der Barrierefreiheit aus?
Ein Formular wird erwartet und es kommt nur ein Link?
Sauber finde ich es nicht, einen Tag für etwas anderes als seine Bestimmung zu verwenden.
„Ich frage mich, ob das Maskieren von Footer-Links wie z.B. dem Impressum und der Datenschutzseite wirklich sinnvoll ist.“
In meinen Augen NEIN! Google erkennt diese und kann diese Einordnen und wird diesen Links sicher auch weniger Bedeutung beimessen.
Danke Daniel für den leicht verständlichen Beitrag. Ich frage mich, ob das Maskieren von Footer-Links wie z.B. dem Impressum und der Datenschutzseite wirklich sinnvoll ist. Du hast am Ende auch ein „natürliches Linkprofil“ erwähnt, wenn man sich also die Masse von Websiten anschaut, wird es sicherlich „natürlich“ sein, dass bei den meisten Webseiten viele interne Links im Footer auf das Impressum weisen, oder durch den Cookie-Consent-Banner auch auf den Datenschutzbereich. Würde es daher nicht unnatürlich wirken, wenn eine Website diese Signale plötzlich nicht hat?
Beste Grüße
Björn
Dieser Gedanke kam mir auch. Und: „Entgegen der landläufigen Meinung wird durch die Verwendung von NoFollow kein Linkjuice eingespart, sondern lediglich entwertet.“ Hast du dazu eine Quelle von Google für den Anwendungsfall nofollow Link auf eine noindex Seite?
Zum Thema Nofollow bei internen Links kann ich folgendes YouTube-Video von Google empfehlen:
Should I use the nofollow attribute on internal links?
https://www.youtube.com/watch?time_continue=1&v=4SAPUx4Beh8
Für weitere Informationen zu Nofollow oder Noindex kann dir vielleicht unser Glossar-Eintrag weiterhelfen:
https://www.seo-trainee.de/glossar/nofollow/
Hi Björn,
danke für deine Frage!
Am Ende des Artikels bezieht Daniel sich auf die Natürlichkeit des Backlink-Profils. Hier geht es also um externe Links. Es wäre unnatürlich, nur externe Links zu bekommen und keine zu vergeben. Deshalb sollte man Links zu anderen Seiten nicht über ein PRG Pattern maskieren.
Hinsichtlich der internen Linkstruktur gibt es, soweit ich weiß, kein „natürliches“ Profil. Bei der Vielzahl an bestehenden Websites vom Onepager bis zum Onlineshop wäre das auch schwierig zu bestimmen. Zudem ist es jedem Webmaster überlassen, innerhalb seiner eigenen Website festzulegen, welche seiner Seiten er selbst für wichtig hält und welche nicht. Wichtig ist hier nur, dass alle Links, die von Suchmaschinen gecrawlt werden sollen, zumindest einmal leicht zugänglich gemacht werden.
Beste Grüße,
Martin
Moin!
Sehr schöner Artikel der das PRG Pattern für SEO detailliert und einfach verständlich erklärt.
Wir haben PRG Pattern bereits in mehreren Kunden-Projekten für die SEO Optimierung der Layered Navigation eingesetzt und können die genannten Vorteile nur bestätigen.
Aufgrund der guten Erfahrungen mit dieser Methode haben wir mittlerweile auch eine Extension für Magento 2 veröffentlicht:
https://www.jajuma.de/de/jajuma-develop/extensions/prg-pattern-link-maskierung-fuer-magento-2
Das Argument bzgl. aufwändiger und mühevoller Umsetzung zählt also zumindest für Magento Shops nicht mehr 🙂