Was ist eigentlich Neural Matching? Gab es schon wieder ein Google Update? Und ist die letzte Sicherheitslücke bei Facebook jetzt geschlossen worden? Antworten auf diese Fragen und weitere aktuelle Nachrichten aus der SEO- und Online-Marketing-Welt findet Ihr in unserem SEO-Wochenrückblick!
Neural Matching
Zum 20. Geburtstag hatte Danny Sullivan eine Reihe von Tweets veröffentlicht, in denen er die anstehenden Updates in der Google-Suche angekündigt hat. Dabei erwähnte er auch ein neues Verfahren: Neural Matching, also frei übersetzt ’neurales Zuordnen‘. Aus dem Tweet geht hervor, dass es dabei um eine KI-gestützte Methode geht, die Synonyme oder anders ausgedrückt die Konzepte hinter Worten besser verstehen kann. Diese Methode würde schon jetzt die Ergebnisse von 30 % der Suchanfragen beeinflussen.

Das klingt doch spannend! Deshalb haben wir einige Nachforschungen angestellt. Dabei sind wir auf den Artikel „What is Google’s Neural Matching Algorithm?“ von Roger Montti im SearchEngineJournal gestoßen. Dieser Artikel stellt die Verbindung zwischen Danny Sullivans Tweet und einem wissenschaftlichen Forschungsbericht her, der kürzlich im Google-AI-Blog veröffentlicht worden ist. Der Forschungsbericht „Deep Relevance Ranking using Enhanced Document-Query Interactions“ von McDonald, Brokos und Androutsopoulos beschäftigt sich mit einem neuen Modell, das Dokumente nach Relevanz ranken soll. Dabei nutzt ein künstliches, neuronales System aber nur die Suchanfrage und den Text der Dokumente selbst. Andere Rankingfaktoren, wie das Feedback von Nutzern oder Signale aus einem Netzwerk (Links), spielen dabei keine Rolle (McDonald et al. 2018: 1).
Im Allgemeinen könne man Methoden, um Dokumenten nach Relevanz zu ranken, in zwei Kategorien einsortieren: auf Repräsentation basierende oder auf Interaktion basierende Systeme. Bei Methoden, die auf Repräsentation basieren, wird der Sinn der Suchanfrage und Worten im Dokument unabhängig voneinander festgelegt und dann miteinander abgeglichen. Bei interaktionsbasierten Systemen wird der Sinn eines Wortes durch das Zusammenspiel von Begriffen aus der Suchanfrage sowie dem Dokument und dem Kontext, in dem die Begriffe stehen, erzeugt. So können Begriffe erkannt werden, die in einem anderen Zusammenhang unterschiedliche Bedeutungen haben. Es können aber auch verschiedene Begriffe gefunden werden, die je nach Kontext dasselbe bedeuten können, also Synonyme sind (McDonald et al. 2018: 2).
Einfacher ausgedrückt: bei der auf Repräsentation basierenden Methode bekommt jedes Wort eine feste Bedeutung. Passen die Bedeutung der Worte einer Suchanfrage nicht zum Text, ist das Dokument nicht relevant für die Suchanfrage. Bei der interaktionsbedingten Methode versucht die künstliche Intelligenz das Konzept hinter den verwendeten Worten zu verstehen. Was kann das Wort alles bedeuten, wenn man es mit anderen Worten zusammen verwendet? Ändert sich die Bedeutung je nach Kontext?
Das Problem bei dieser Methode ist, dass Dokumente, die auf diese Weise verstanden werden, nicht effizient indexiert werden können. Sie müssten immer in Verbindung mit der Suchanfrage gespeichert werden, da sich der erkannte Zusammenhang von Begriffen auf die jeweilige Suchanfrage bezieht. Im Forschungsbericht von McDonald et al. 2018 wird deswegen die interaktionsbasierte Methode zur Relevanzbestimmung erst eingesetzt, nachdem die Dokumente von einem herkömmlichen Suchalgorithmus vorsortiert worden sind. Der auf Repräsentation basierende Algorithmus filtert gewissermaßen den Spam aus den Dokumenten. Daraufhin ordnet das interaktionsbasierte Modell die vorsortierten Dokumente nach der Relevanz ihrer Texte in Bezug zur jeweiligen Suchanfrage.
Es ist natürlich nicht sicher, dass Google genau dieses Modell in seinem Suchalgorithmus verwendet.
Die vorgestellte, interaktionsbasierte Methode, um Dokumente nach Relevanz zu ranken, könnte aber durchaus ein Teil von Googles Neural Matching sein. Google selbst beschrieb dieses Vorgehen nämlich auch wie folgt: „Neurale Netzwerke haben große Fortschritte darin gemacht, nicht nur Worte, sondern Konzepte zu verstehen. Worte können nun in Repräsentationen von unschärferen Konzepten umgewandelt werden, wodurch die Konzepte in Suchanfragen mit den Konzepten im Dokument verglichen werden können. Wir nennen diese Technik Neural Matching“ (Google-Blog „The Keyword„).
Natürlich wird es an dieser Stelle nichts helfen, wenn Ihr jetzt noch ein paar Synonyme mehr in Eure Texte reinpresst. Das allein wird auch in Zukunft nicht für bessere Rankings sorgen. Stattdessen zeigt diese Entwicklung, wie wichtig es ist, die Suchintention hinter Keywords zu verstehen und entsprechend nützlichen Content zur Befriedigung dieser Intention zu erstellen.
Google News
- Anpassung des Algorithmus‘ zu Googles Geburtstag: Danny Sullivan hat bestätigt, dass es letzte Woche ein kleineres Update von Googles Suchalgorithmus gegeben hat. Was genau angepasst worden ist, wurde wie so oft nicht genauer erklärt. Vermutungen und Feedback zum „Birthday Update“ findet Ihr auf SearchEngineRoundtable.
- Meta-Daten bezüglich Bildrechten jetzt in der Google Bildersuche: Im Google-Blog „The Keyword“ hat die Suchmaschine diese Woche angekündigt, dass zwei neue Meta-Tags für Bilder in der Google Bildersuche angezeigt werden können. Diese sollen darüber Auskunft geben, wer über die Rechte an dem Bild verfügt. Tipps zur Implementierung dieser Metadaten könnt Ihr den IPTC-Richtlinien entnehmen. Die beiden Tags sind:
- Creator: Name des Photographen
- Credit: Information über den oder die Herausgeber des Bilds, die genutzt werden muss, wenn das Bild veröffentlicht wird
- Googles Dokumentation zu Dynamic Rendering: Im Mai hat John Mueller versprochen, dass es bald eine Dokumentation bezüglich des Google-konformen Einsatzes und der Umsetzung von Dynamic Rendering geben wird. Jetzt ist es so weit! Mit Dynamic Rendering könnt Ihr Crawlern direkt vom Server eine vorgerenderte Version Eurer Website zur Verfügung stellen. Dadurch wird es für die Bots einfacher, JavaScript-Elemente zu crawlen. Wenn Nutzer hingegen Eure Website aufrufen, übernimmt weiterhin deren Browser das Rendern.
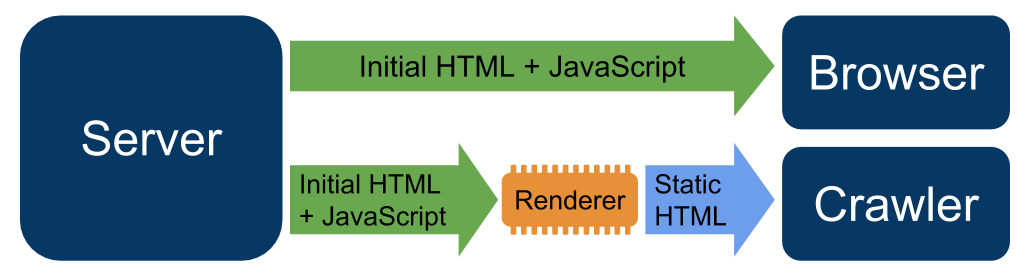
- Informationen aus der Search Console direkt in den Suchergebnissen: Für Suchanfragen, die für die eigene Website relevant sind, zeigt Google aktuell für ausgewählte Accounts Daten aus der Google Search Console wie Klicks, Impressionen und durchschnittliche Position direkt in der Suche an. Zusätzlich muss man dafür mit seinem Google Account eingeloggt sein. Es ist im Moment wohl nur ein Test. Aktuelle Sichtungen könnt Ihr auf SearchEngineRoundtable nachvollziehen.
Vermischtes
- Sicherheitslücke bei Facebook geschlossen: Nachdem ungefähr 50 Million Accounts von einer Sicherheitslücke betroffen waren, hat Facebook ein Login Update umgesetzt. Bislang unbekannte Hacker hatten mittels digitalen Schlüssel Zugriff auf User-Daten, wie zum Beispiel Wohnort, Geschlecht, Alter, erhalten. Das Problem hat Facebook inzwischen behoben. Im Zuge dessen hat das Soziale Netzwerk den Login von insgesamt 90 Millionen Accounts zurückgesetzt.
- Neue Suchmaschine für Recruiter: Habt Ihr Euch schon immer eine Suchmaschine gewünscht, mit deren Hilfe Ihr potenzielle Arbeitnehmer für Eure offenen Stellen finden könnt? Findera möchte genau das möglich machen. Dazu könnt Ihr bei der neuen Suchmaschine direkt nach dem Namen Eurer Wunschangestellten suchen. Alternativ könnt Ihr auch verschiedene Filter wie beispielsweise Abteilung, Position, Ort oder Unternehmen nutzen, um eine Auswahl von passenden Kandidaten zu erhalten. Anschließend ist es möglich, diese Daten zu exportieren. Die Daten bekommt Findera nach eigenen Angaben durch das Crawlen von öffentlichen Websites, die Kontaktinformationen eingeloggter Nutzer oder aus frei verfügbaren Datenbanken, die große Unternehmen zur Verfügung stellen.
- Was tun, wenn Google auf den SERPs selbst alle Antworten gibt? Mit Featured Snippets, Direct-Answer-Boxen, Knowledge Panels und verschiedenen Karussellen mit News, Bildern, Videos oder Tweets wird Google selbst immer mehr zum ärgsten Ranking-Konkurrenten. Darum hat der Rank-Ranger-Blog diese Woche eine Reihe Experten nach Strategien und Maßnahmen gefragt, wie man gegen all diese Features ankommen oder wie man sie sich zunutze machen kann. Die Empfehlungen reichten dabei vom Aufbau seiner eigenen Marke über die Nutzung strukturierte Daten bis hin zur Neuausrichtung seiner Keyword-Strategie und Erweiterung seines Themenspektrums.
Unsere Tipps der Woche
- karlsCORE public Konferenz – 26.10.2018 in Berlin: Ihr liebt Karl Kratz als Sprecher bei Online-Marketing-Konferenzen? Ja? Wie wäre es dann mit einer ganzen Online-Marketing-Konferenz, die von Karl organisiert wird? Bei der karlsCORE public Konferenz werden mehr als 220 Experten der Branche zusammenkommen und sich austauschen. Dazu wird es zehn hirngerechte Impulsvorträge geben. Dabei wird es um die Entwicklung digitaler Strategien, die Erstellung von Inhalten, SEO und Conversion-Optimierung gehen. Teilnehmen könnt Ihr aber nur, wenn Ihr Euch heute noch über Euren karlsCORE-Zugang anmeldet. Jetzt aber schnell!
- New Marketing Tech Summit – 07.11.2018 in Hamburg: Im Online-Marketing gibt es immer mehr technologische Möglichkeiten, um beispielsweise Kunden individuell anzusprechen und datenbasiert Entscheidungen zu treffen. Welche Marketing-Technologien wirklich relevant sind und welche Rolle der Mensch im Marketing der Zukunft spielen wird, erfahrt ihr beim New Marketing Tech Summit. Bezahlt mit dem Rabattcode NMTS18RABSEOTRAINEE 20 % weniger für das Ticket zum Summit!
- DISRUPTION – 23.10.2018 in München: Bei dieser Konferenz geht es um die Disruption bestehender Geschäftsmodelle und tradierte Wertschöpfungsstrukturen – kurz: um die digitale Revolution! Seid dabei, wenn Entscheidungsträger aller Art auf der Bühne bei der DISRUPTION 2018 über die Digitalisierungsprozesse in ihren Unternehmen berichten und sich neben der Bühne darüber austauschen. Eins von vier Tickets könnt Ihr dafür bei unserer Verlosung gewinnen!
Ein schönes Wochenende wünschen Euch
Martin und die SEO-Trainees



