Ist das heiß da draußen! Zum Glück kann man unseren SEO-Wochenrückblick von mobilen Endgeräten auch im Pool oder zumindest mit einem Eis in der Hand lesen. Dieses Mal geht es um die aktuellen Anpassungen im Leitfaden für die Qualitätsbewerter der Google-Suche, die konsistente Verwendung von rel=canonical und Amazon-SEO. Zögert nicht und lest Euch rein!
Guter Content nach Googles Leitfaden für Qualitätsbewerter
Google beschäftigt weltweit 10.000 sogenannte „search quality raters“, also Qualitätsbewerter für die Google-Suche. Diese werden damit beauftragt, nach bestimmten Begriffen zu suchen und daraufhin die Qualität der Ergebnisse auf der ersten Seite zu diesen Suchanfragen zu bewerten.

Diese Bewertungen haben keinen direkten Einfluss auf die Rankings von Websites. Allerdings nutzt Google die Bewertungen, um seinen Suchalgorithmus zu verbessern. Dabei wird abgeglichen, ob der Algorithmus qualitativ hochwertige Seiten gut rankt oder nicht. Sollte es hier zu Unstimmigkeiten kommen, wird der Algorithmus dann gegebenenfalls angepasst. Auf diese Weise beeinflussen die Qualitätsbewertungen eher indirekt und langfristig die Rankings.
Seit einiger Zeit hat Google auch den Leitfaden, auf dessen Grundlage die Bewertungen stattfinden, öffentlich zugänglich gemacht. Dieser Leitfaden ist diese Woche in bestimmten Punkten angepasst worden. Diese Anpassungen können Euch ein gutes Bild vermitteln, wie Google guten Content definiert. Wir haben im Folgenden die wichtigsten Änderungen und Erkenntnisse für Euch zusammengefasst. Eine ausführliche Analyse des Updates findet Ihr bei TheSEMPost im Artikel „Google Search Quality Rater Guidelines Updated: Beneficial Purpose, Creator Reputation & More“ von Jennifer Slegg.
Bewertungsfaktoren
Im Folgenden werden die Faktoren aufgelistet, die in die Qualitätsbewertung der Webseiten einfließen sollen.
Seiten, die Hass verbreiten, Schaden verursachen (Malware, Phishing), desinformieren oder Nutzer täuschen wollen, sollen ohne weitere Beurteilungen des Inhalts die schlechteste Bewertung bekommen.
Davon abgesehen sollen die Inhalte nach folgenden Bewertungsfaktoren beurteilt werden:
- Dem Zweck der Seite
- Der Erfahrung, der Autorität und die Vertrauenswürdigkeit der Quelle.
- Der Qualität und der Länge des Hauptinhalts.
- Dem Ruf der Webseite oder des Autors der Inhalte.
Die Absicht zur Schaffung von Mehrwert
Zunächst sollen die Bewerter nicht mehr nur auf die Qualität der Inhalte achten. Zusätzlich sollen sie feststellen, ob die Seite die Absicht hat, dem Nutzer einen Mehrwert zu bieten oder ob sie für Nutzer in irgendeiner Form nützlich ist. Ist dem nicht der Fall, soll die Seite die schlechteste Bewertung bekommen.
Qualitativ minderwertiger Content
Der angepasste Leitfaden für Qualitätsbewerter legt nun fest, dass die Inhalte von Webseiten von schlechter Qualität sind, wenn sie die Absicht, dem Nutzer Mehrwert zu bieten, nicht erfüllen können. Dies kann erstens daran liegen, dass der Hauptinhalt zu kurz ist und dadurch nicht genügend Informationen liefert. Zweitens kann dem Autor des Hauptinhalts die nötige Erfahrung, Autorität oder Vertrauenswürdigkeit fehlen, um dem Zweck der Webseite gerecht zu werden. Drittens kann schlechte Pflege oder die mangelhafte, technische Umsetzung der Website dazu führen, dass der Inhalt der Seite seinen Zweck nicht erfüllen kann.
Zudem sollen Webseiten schlecht bewertet werden, die übertreibende oder schockierende Titel (Click-Bait-Titel) für Artikel nutzen, die nicht liefern, was die Titel versprechen. Das Gleiche gilt für Webseiten, die versuchen Ihre Nutzer auszutricksen, damit diese auf einen Link klicken.
Auch ablenkende Werbeanzeigen sollen zu schlechten Bewertungen führen.
Neuerdings fordert der Leitfaden die Qualitätsbewerter zudem auf, sich zusätzlich über den Ruf des Autors der Inhalte der zu bewertenden Seite zu informieren. Vorher ging es immer nur um den allgemeinen Ruf der Website. Sind über den Autor ohne guten Grund für Anonymität keine Informationen zu finden oder verfügt der Autor über einen schlechten Ruf, sind dies Gründe für eine schlechte Bewertung.
Fazit
Bei der Erstellung von Webseiten und Inhalten sollten wir uns immer fragen, welchen Mehrwert diese für unsere Nutzer schaffen sollen. Daraufhin sollten wir sicherstellen, dass der Nutzer tatsächlich diesen Mehrwert auch in Anspruch nehmen kann. Die Wahl von Inhalten, Titeln, Ads und Links sollte von diesen zwei Punkten maßgeblich bestimmt werden.
In Zukunft sollte zudem jeder Artikel, der auf unseren Webseiten veröffentlicht wird, auch Informationen zum Autor bereitstellt (bspw. Name, Alias, Biographie, Social Links etc.). Dies gilt besonders für Seiten, die nicht standardmäßig eine Verfasserzeile zu ihren Inhalten veröffentlichen und somit nicht klar ist, wer die Inhalte verfasst hat.
Google News
- Konsistenter Einsatz von rel=canonical: Wie legt Google bei verschiedenen URLs, die sich sehr ähnlich sind, fest, welche die ursprüngliche oder wichtigste Version dieser URLs ist? In einem Reddit Thread erklärte John Mueller, dass Google versucht, URLs, die sich kaum unterscheiden, zu kombinieren und als eine, stärkere URL zu behandeln. Ihr könnt Google mit Hilfe verschiedener Signale wie Redirects, rel=canonical, internen und externen Links, sowie Sitemaps und hreflang klar machen, welche URL Ihr als kanonische Seite präferiert. Werden diese Signale konsistent genutzt, folgt die Suchmaschine dieser Präferenz. Inkonsistente Signale können diesen Prozess jedoch stören. Das Noindex-Tag alleine würde Google zum Beispiel sagen, dass die Seite unwichtig ist und nicht, dass diese Seite mit einer anderen kombiniert werden soll. Deshalb solltet Ihr auf einer Seite nicht gleichzeitig noindex und rel=canonical nutzen. Auch kann Google keine Seiten kanonisieren, die durch die robots.txt vom Crawling ausgeschlossen werden. Eine Antwort von Mueller auf eine Frage auf Twitter zeigte diese Woche weiteres Störpotenzial bei der Kanonisierung auf: Die Paginierung von Seiten mit rel=next/pref zeigt an, dass unterschiedliche Seiten aufeinander folgen. Deswegen ist es nicht sinnvoll paginierten Seiten zusätzlich mit rel=canonical auszuzeichnen, da auch dies widersprüchliche Signale an die Suchmaschine sendet.
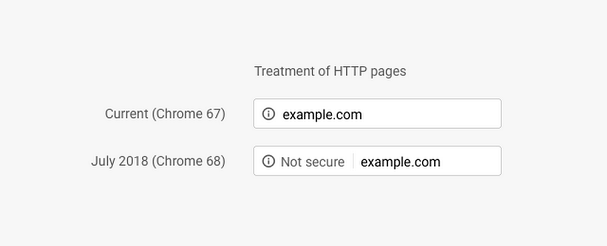
- Sichtbare Sicherheitswarnung bei HTTP-Seiten in Chrome: Google hat diese Woche über seinen offiziellen Blog „The Keyword“ angekündigt, dass die neuste Chrome-Version (68) jetzt sichtbar vor HTTP-Seiten als „Not secure“, also „Nicht sicher“, warnt. Google möchte damit Nutzer darüber informieren, dass Verbindungen mit HTTP-Seiten nicht verschlüsselt werden. Zudem sollen Website-Betreiber motiviert werden, die Sicherheit ihrer Seiten zu erhöhen und ihre Websites auf HTTPS umzustellen. Als nächstes plant Google im Oktober diese Sicherheitswarnung rot aufleuchten zu lassen, wenn Nutzer Daten in Formulare von HTTP-Seiten eingeben.
- Strukturierte Daten für „vorlesbar“ Passagen in Nachrichtenartikeln: Google hat eine neue Möglichkeit vorgestellt, wie Herausgeber von Nachrichten relevante Passagen ihrer Artikel auszeichnen können, damit der Google Assistant sie laut vorgelesen kann. Das Markup „speakable“ von schema.org kann von Publishern mit entsprechender Berechtigung in den USA für englischsprachige Artikel genutzt werden. Google hat in Aussicht gestellt, dass dieses Feature auch in anderen Sprachen und Ländern verfügbar sein wird, sobald genug Herausgeber das neue Markup implementiert haben.
- KI-Experimente selbst ausprobieren: Kennt Ihr schon Googles Seedbank? Dies ist eine Datenbank für KI-Experimente, die mit Hilfe des Forschungstools Colaboratory dokumentiert worden sind. Die Seedbank soll Nutzern ermöglichen, verschiedene Projekte rund um maschinelles Lernen zu finden, zu testen und in eigenen Anwendungen umzusetzen. Die Datenbank ist aber nicht nur für Entwickler interessant, sondern auch ein guter Ort, um sich inspirieren zu lassen, wofür man KI alles einsetzten kann.
Vermischtes
- Amazon-SEO für mehr Verkäufe: Die erste Anlaufstelle bei der Suche nach Produkten ist oft Amazon. Fast die Hälfte aller Deutschen startet die Suche mittlerweile bei dem Online-Riesen. Damit das eigene Produkt in der Masse performt, gilt es den Produkttitel, die Bulletpoints, Schlüsselwörter, Produktbeschreibung und die Produktbilder richtig zu optimieren. Onlinemarketing.de gibt Euch entsprechend fünf Amazon-SEO-Tipps, die aufzeigen, wie solche Optimierungen aussehen sollten.
- Fast jeder zehnte Instagram-Account gehört einem Bot: t3n stellte diese Woche eine Studie von Ghost Data vor, nach der 95 Millionen der ungefähr einer Milliarde Instagram-Accounts gar nicht echt seien. Hinter diesen Fake Accounts würden sich vor allem Bots verstecken. Im Influencer Marketing ginge es auch deshalb schon lange nicht mehr nur um Follower-Zahlen, sondern darum, einen Influencer mit der qualitativ passenden Zielgruppe zu finden.
- Neues Tool soll den Datentransfer zwischen Apps erleichtern: Wie horizont.net diese Woche berichtete, haben Facebook, Google, Twitter und Microsoft ihr sogenanntes „Data-Transfer-Project“ vorgestellt. Im Zuge dessen soll ein neues Tool entwickelt werden, welches es künftig mithilfe bestehender APIs und besonderer Adapter möglich machen soll, Nutzerdaten einfach zwischen Plattformen und Anwendungen zu transferieren.
- Wer setzt in Eurer Branche aktuelle Webstandards am besten um? Bei der Umsetzung von „Best Practices“ bezüglich Eurer Website kann es manchmal ganz hilfreich sein, sich ein gutes Beispiel anzusehen. Das Tool Audisto Industry Monitor bewertet und rankt große Portale, Onlineshops und Websites aus verschiedenen Branchen nach der Umsetzung aktueller technologischer Standards. Dem „AO Score“ könnt Ihr den Optimierungsgrad der Websites der Branchenführer hinsichtlich Sicherheit, Performance, Technologie und Content entnehmen.

Ein schönes Wochenende wünschen Euch
Martin und die SEO-Trainees



