Bei SEO spielen eine Menge Faktoren eine Rolle. Einen wesentlichen Einflussfaktor stellt das Crawling und Indexing der Suchmaschine dar. In unserem Top-Thema möchten wir dieser Thematik auf den Grund gehen und beleuchten dabei einige Vorgehensweisen, wie Ihr Euer Crawl-Budget effizienter nutzen könnt. Außerdem haben wir wie immer die wichtigsten Google-News für Euch zusammengefasst.
Wieso ist Crawl-Budget-Optimierung wichtig?
Mit Crawl Optimization sind Maßnahmen gemeint, die zu einer effektiveren Nutzung des Crawl Budgets führen sollen. Besonders für umfangreichere Websites hat das Thema eine große Bedeutung. Google legt ein individuelles Crawl-Budget für jede Domain fest. Wie sich dies zusammensetzt, klären wir im weiteren Verlauf für Euch. Doch zunächst wollen wir die Grundlagen durchgehen.
Für die Aufarbeitung des Themas haben wir einen Artikel von Seobility sowie einen Vortrag von Martin Splitt genauer unter die Lupe genommen.
Was ist das Crawl Budget?
Damit Ihr die Bedeutung des Crawl-Budgets gut nachvollziehen könnt, ist das Verständnis von zwei grundlegenden Begriffen die Voraussetzung:
- Crawl Rate: Wie oft können Seiten von Eurer Website pro Sekunde gecrawlt werden? Entscheidend ist hierbei, wie schnell Euer Server auf die Anfragen antworten kann bzw. ob irgendwelche Fehlermeldungen vorliegen.
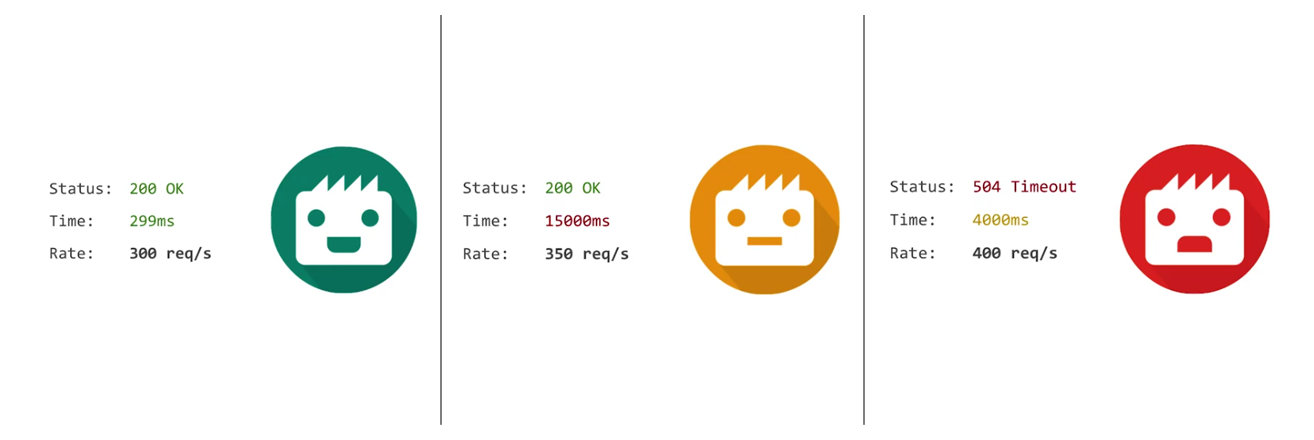
Je höher die Anzahl der Serverabfragen, desto höher die Belastung. Dies wirkt sich negativ auf die Ladezeit Eurer Seite aus. ©Martin Splitt - Crawl Demand: Werden auf Seiten regelmäßig neue Inhalte veröffentlicht und verfügen zudem über ein großes Backlink-Profil, werden sie häufiger gecrawlt. Erkennt der Crawler, dass sich Inhalte bestimmter Seiten einer Website nicht ändern und weniger Backlinks auf diese verweisen, werden diese folglich weniger oft gecrawlt.
Seobility fasst Crawl Budget wie folgt zusammen: „[…] das Crawl Budget [beschreibt] somit die Anzahl an URLs [Eurer] Website, die der Googlebot aus technischer Sicht crawlen kann und aus inhaltlicher Sicht auch crawlen möchte.“
Google setzt beim Crawling bewusst Limits. Grund ist, dass die angesprochene Serverbelastung zu einer längeren Wartezeit und somit zu einer schlechteren User Experience bei Nutzern führen kann.
Was kann sich negativ auf Euer Crawl Budget auswirken?
Es gibt dutzende Möglichkeiten, wie Crawl Budget unnötig verschwendet werden kann. Wir wollen Euch nun aus unserer Sicht drei weit verbreitete Aspekte veranschaulichen. Im Anschluss stellen wir mögliche Lösungsansätze vor.
Duplicate Content
Über dieses Thema haben wir in unserem Wochenrückblick der KW 22 berichtet. DC hat im Index nichts verloren. Wenn identische Inhalte mehr als einmal gecrawlt werden, ist dies eine Verschwendung des Crawl Budgets. Parameter-URLs sind ein Beispiel für mögliche Quellen für Duplicate Content.
- Mögliche Lösungsansätze: Indexierten Duplicate Content mit Noindex-Meta-Tags Nun sollte abgewartet werden, bis die entsprechenden Seiten aus dem Index entfernt werden. Wurden sie aus dem Index entfernt, solltet Ihr sie zum Abschluss noch mithilfe der Robots.txt blocken. Achtet generell darauf, dass Seiten, die Ihr mittels der Robots.txt blockt, auch nicht mehr intern oder extern verlinkt werden. Ist dies nämlich der Fall, können dieses URLs in den Indexierungsprozess nach wie vor mit einbezogen werden. Werden Seiten auf diese Art blockiert, bedeutet dies aber auch, dass wichtige Meta-Daten verloren gehen können. Google kann beispielsweise keine Canonical Tags dieser Ressourcen mehr beachten.Allerdings muss auch klar sein, dass genau hingeschaut wird, was entfernt werden kann und was nicht. Parameter-URLs, die beispielsweise unterschiedliche Eigenschaften eines Produktes angeben, müssen für Nutzer zugänglich sein. In diesem Fall sollte ein Canonical Tag gesetzt werden. Google crawlt dennoch alle URLs, die mit Canonical Tags versehen sind und entscheidet selbst, welche URL die kanonische ist und somit indexiert wird.
Soft Errors
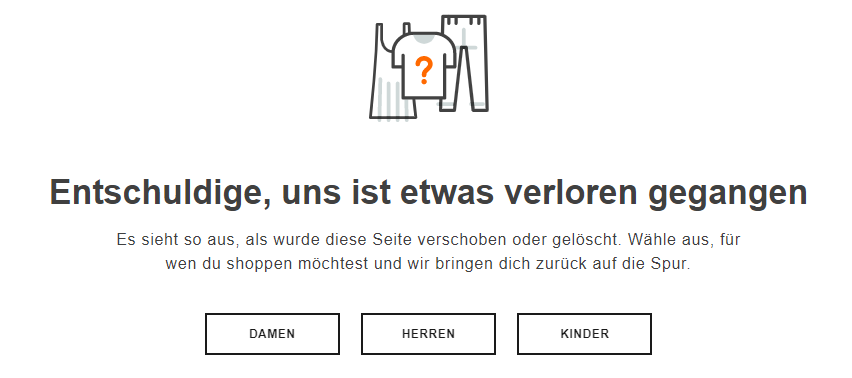
In diesem Fall handelt es sich um Seiten, bei denen der Server einen Statuscode 200 anzeigt. Auf den ersten Blick ist also alles in Ordnung. Dem Nutzer wird hingegen eine 404-Fehlerseite ausgespielt.

Die Inhalte der Webseite passen folglich nicht mit der HTTP-Antwort des Servers zusammen. Für das Crawling bedeutet dies im Umkehrschluss, dass Seiten mit fehlerhaften Inhalten unnötigerweise gecrawlt werden und somit Crawling-Budget verschwendet wird.
- Mögliche Lösungsansätze: Wenn Ihr Eure Website mit Tools, wie beispielsweise Screaming Frog crawlt, solltet Ihr Euch identische Titles oder Meta Descriptions anschauen. Die Wahrscheinlichkeit ist hoch, dass diese bei Soft-404-Seiten übereinstimmend sind und somit leicht identifiziert werden können. Schaut Euch auch die Weiterleitungen an. Leiten Seiten auf die Startseite weiter, kann dies ein Hinweis auf Soft 404-Fehler sein. 301-Weiterleitungen sollten in diesem Fall nicht auf die Startseite führen. Die Inhalte der Startseite unterscheiden sich zu den Inhalten von Unterseiten. Die Bedürfnisse des Nutzers werden auf diese Weise also nicht befriedigt. Ideal wäre beispielsweise eine 404-Fehlerseite, die den Nutzern verschiedene Optionen bietet.
Weiterleitungsketten
Mehrere Weiterleitungen, die direkt aufeinanderfolgen, werden Weiterleitungsketten genannt. Solche Ketten sind nicht gut für eine effiziente Nutzung des Crawl Budgets, weil mehrere nicht relevante Seiten durch den Googlebot aufgerufen werden müssen bis die eigentlichen Inhalte geladen werden.
- Mögliche Lösungsansätze: Zunächst einmal gilt es, Weiterleitungsketten zu erkennen. Hier wäre beispielsweise das bereits erwähnte Tool Screaming Frog geeignet. In den Voreinstellungen sollte „Always Follow Redirects“ eingestellt werden. Somit werden alle Weiterleitungen gecrawlt. Ist der Crawl abgeschlossen, kann in dem Tool zusätzlich eine Crawl-Analyse durchgeführt werden. Dies ermöglicht das Abrufen verschiedener Reports. Unter anderem kann nun der Report „Redirect and Canonical Chains“ heruntergeladen werden.


Nachdem Ihr das getan habt, erhaltet Ihr eine umfangreiche Excel-Datei. Um Weiterleitungsketten zu erkennen, muss diese ein wenig bearbeitet werden.
![]()
Die Grafik zeigt einen bearbeiteten Ausschnitt. Eigentlich ist der Report noch ein wenig umfangreicher. Beispielsweise werden HTTP-Statuscodes der einzelnen URLs angezeigt. Wie kann eine Bearbeitung aussehen? Zunächst sollten mit Textfiltern unwichtige Daten ausgeschlossen werden.
- Bei „Chain Type“ auf „HTTP Redirect“ filtern, sodass nur Weiterleitungen angezeigt werden.
- Die „Number of Redirects“ sollte immer über 1 liegen, da es sich ansonsten nicht um eine Weiterleitungskette handelt.
- Die „Source“ zeigt nun, wo die Seite intern verlinkt ist. Bei „Adress“ handelt es sich um die Ressource, die weitergeleitet wird.
- „Final Adress“ ist die URL am Ende der Weiterleitungskette. „Redirect URL 1/2“ sind die unterschiedlichen URLs der Weiterleitungen.
- Es sollte direkt die „Final Adress“ verlinkt werden, um Crawl Budget zu sparen und für einen besseren Link Juice zu sorgen.
Fazit
Es gibt sehr viele unterschiedliche Arten, wie eine Verschwendung von Crawl Budget entstehen kann. Besucht gerne den Artikel von Seobility, um Euch über weitere Möglichkeiten zu informieren.

Google News
Neues Design der Google News-Ergebnisse könnte Einfluss auf Traffic haben: Wie die Website Search Engine Roundtable berichtete, wird die Desktopversion der Suchergebnisse für Google News nun in einem neuen, kartenähnlichen Design angezeigt werden. Es wurde jedoch nicht nur das Aussehen der Suchergebnisse geändert, sondern ab sofort wird nun auch für eine Meldung jeweils nur noch eine Quelle angezeigt. Dadurch kann es zu größeren Traffic-Schwankungen für Google News-Publisher kommen. Profitieren können hier bekannte und häufig angezeigte Quellen, für kleinere Publisher kann dies jedoch zu einem enormen Abfall des Traffics führen.
Probleme bei der Nutzung des URL-Parameter-Tools: SEO-Südwest berichtete nun, dass bei der Verwendung des URL-Parameter-Tools in der Google Search Console oftmals so gravierende Fehler geschehen, dass Google die Webmaster benachrichtigen muss. Dies diskutierte John Mueller in einem aktuellen Webmaster Hangout. Solche Fehler können letztendlich sogar zu einem unvollständigen Crawlen der Seite führen. Daher ist es empfehlenswert, dieses Tool nur zu verwenden, wenn Klarheit über die Auswirkungen der URL-Parameter besteht.
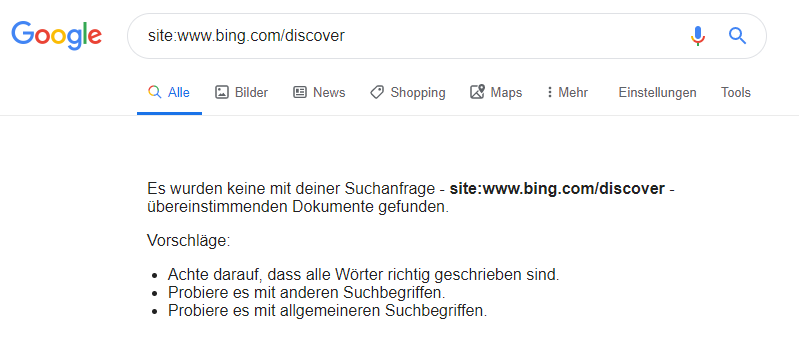
Google de-indexiert Bing Discover-Seiten: Bereits Anfang des Monats stoppte Google den Referral-Traffic für den Bing Discover-Bereich und de-indexierte diesen sogar, wie in unserem Screenshot deutlich wird. Nun geht die Website Search Engine Land in einem neuen Blogbeitrag darauf ein, was die Gründe für diese Maßnahmen seitens Google sein könnten. Entdeckt wurde dies durch den organischen Traffic-Verlust, des Bing Discover-Bereiches. Der Hauptgrund für das Verhalten von Google wird darauf zurückgeführt, dass Bing lange Zeit Google ausnutzte, um enormen Traffic für sich zu gewinnen. Genaueres hierzu findet Ihr in einem Artikel von Roey Skif. Search Engine Land erklärt auch, dass dieser Vorfall zeigt, dass die Guidelines von Google eingehalten werden sollten und Webmaster keine Verluste von guten Rankings und wertvollem Traffic durch grenzwertige Methoden riskieren sollten.
Sicherheitslücken im Chrome-Browser – Google empfiehlt Update: Wie der Google Watch Blog nun berichtete, legt Google seinen Nutzern nun nahe, so schnell wie möglich das bereitgestellte Sicherheitsupdate für den Chrome-Browser durchzuführen, da Google zwei größere Sicherheitslücken festgestellt hat. Dabei gab Google keine genaueren Informationen über die Probleme bekannt.
“noindex“-Einstellung für RSS-Feeds und XML-Sitemaps: Auf Twitter stellte John Mueller klar, dass sowohl RSS-Feeds als auch XML-Sitemaps auf “noindex“ gesetzt werden können, um zu verhindern, dass diese in den Google-Suchergebnissen erscheinen. Dies hindert Google nicht daran das RSS-Feed und die XML-Sitemap zu verarbeiten. John Mueller sieht dies jedoch als nicht unbedingt notwendig an, da RSS-Feeds und XML-Sitemaps in den Suchergebnissen nur sehr selten vorkommen.
Vermischtes
Google-My-Business-Studie: BrightLocal veröffentlichte diese Woche eine ausführliche Studie, die interessante Insights für Google My Business bietet. Hierbei wurde untersucht, wie Nutzer Google-My-Business-Einträge finden und wie mit ihnen interagiert wird. Dies soll Unternehmen, die Google My Business nutzen, wertvolle Hinweise geben, wie sie ihr Marketing gestalten können. Analysiert wurden 45.000 Einträge aus verschiedenen Branchen und Ländern, um ein umfassendes Bild zu kreieren. Festgestellt wurde hier beispielsweise, dass bereits 25 % der Suchen durch Google Maps generiert werden und sich dieser Trend in den kommenden Jahren höchstwahrscheinlich noch verstärken wird. Wenn Ihr die Ergebnisse der Studie selbst einmal genauer betrachten möchtet, schaut doch einfach mal auf BrightLocal vorbei.
Trackt Facebook hochgeladene Bilder auch außerhalb der Plattform?: Auf Twitter stieß der Cyberforscher Edin Jusupovic das bereits diskutierte Thema, dass Facebook hochgeladene Bilder auch außerhalb der eigenen Plattform trackt, neu an. Hierbei entdeckte er ein Wasserzeichen, mit dem Facebook seine Bilder markiert. Dadurch soll es für Facebook möglich sein, den Weg der Bilder im gesamten Netz verfolgen zu können. Dies kann Facebook zu noch genaueren Nutzerdaten verhelfen.
Was Ihr bei dem Aufbau einer Landingpage beachten solltet: Auf der Website des UPLOAD Magazins wurde nun ein Artikel zu den fünf Kernelementen einer erfolgreichen Landingpage veröffentlicht. Dabei geht der Artikel auf typische Stolpersteine ein sowie auf wesentliche Punkte wie zum Beispiel das Alleinstellungsmerkmal, Social Proof oder auch auf die optimale Gestaltung des Hero Shots.
Unsere Tipps der Woche
Welt-Emoji-Tag – Apple präsentiert neue Emojis: Pünktlich zum Welt-Emoji-Tag, zeigte Apple diese Woche erstmals neue Emojis, die auf iOS Geräten demnächst Einzug halten sollen. Hier wurde besonders darauf geachtet auch andere Bevölkerungsgruppen zu repräsentieren, wie zum Beispiel mit der Option verschiedener Hautfarben oder auch Emojis, die Personen mit Behinderung abbilden. Das Update für die Emojis ist für die zweite Jahreshälfte geplant.

Questions & Answers mit John Mueller: Wie von Google Webmasters auf Twitter nun angekündigt wurde, wird auf dem YouTube-Kanal von Google Webmasters eine Q&A-Reihe mit John Mueller an den Start gehen. Der Unterschied zu dem bereits bestehenden YouTube-Format des Webmaster-Hangouts besteht hauptsächlich in der Aufmachung des Videos. Die neue Serie ist keine Live-Aufnahme, sondern wird im Vorfeld produziert. Den Teaser zu der Q&A-Serie findet Ihr ebenfalls auf dem Twitterprofil von Google Webmasters.
Wir wünschen Euch ein schönes Wochenende!
Janek und die SEO-Trainees




