Es ist Freitag! Natürlich versorgen wir euch auch diese Woche pünktlich zum Wochenende wieder mit den News, die die SEO-Welt beschäftigt haben. Heute im Programm: Nach welchen Kriterien wählt Google Seitentitel aus, was ist überhaupt Passage Retrieval und wieviel kostet ein Tweet von Puff Daddy? Hinsetzen, anschnallen und los geht’s!
Wie wählt Google Titel für Suchergebnisse aus?
In einem neuen Video beantwortet Matt Cutts die Frage, nach welchen Kriterien Google entscheidet, was als Seitentitel in den SERPs angezeigt wird. Die Fragesteller wollten ferner wissen, ob semantische Auszeichnungen mittels schema.org einen Einfluss darauf haben und ob Überschriften wie „H1“ eventuell größere Bedeutung haben. Matt nennt drei Punkte, die die Titelauswahl beeinflussen:
- Der Titel ist kurz
- Der Titel liefert eine prägnante Beschreibung der Seite
- Der Titel korrespondiert mit der Suchanfrage
Erfüllt der Title-Tag auf eurer Seite die genannten Kriterien, übernimmt Google diesen höchstwahrscheinlich und zeigt ihn als Snippet-Überschrift an. Matt empfiehlt weiter, bei der Auswahl des Titels die möglichen Suchanfragen der Nutzer mit einzubeziehen. Spiegelt der Inhalt des Title-Tags die Suchanfrage wider, ist die Wahrscheinlichkeit höher, dass ein Nutzer darauf klickt.
Sie sehen gerade einen Platzhalterinhalt von Youtube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Entspricht der Seitentitel jedoch nicht diesen Kriterien, sucht Google sich selbst Informationen. Diese holt sich der Bot entweder aus dem Seiteninhalt, aus Ankertexten von Links, die zu der Seite zeigen oder aus dem Open Directory Project (DMOZ).
Weiter betont Matt, dass Google den Titel sucht, der am besten zu der Suchanfrage passt und dem Nutzer Relevanz signalisiert. Dieser soll durch den Titel wissen, was er bekommt, wenn er auf das Ergebnis klickt. Allerdings sagt Matt in seinem neuen Video, dass auch der Seiteninhalt nicht vernachlässigt werden sollte. Inhalt und Metaangaben müssen thematisch zueinander passen, sonst kann es zu Verwirrungen bei Google kommen.
Was ist Passage Retrieval?
…Und wofür brauche ich das? Auf SEO Südwest startet in dieser Woche eine neue Beitragsserie zum Thema „Information Retrieval“ (Informationsrückgewinnung). Wir haben uns den ersten Artikel über Passage Retrieval angeschaut und für euch zusammengefasst:
Passage Retrieval bezeichnet einen Spezialfall des Dokumenten-Retrievals. Hierbei werden Dokumente aus einem Fundus (im Retrieval Korpus genannt) in kleinere Stücke zerlegt. Mit verschiedenen Techniken wird die Relevanz dieser Passagen bezüglich der gestellten Suchanfrage ermittelt und eine Rangfolge erstellt.
Die Segmentierung eines Dokuments kann anhand struktureller (z. B. Kapitel) oder semantischer Aspekte vorgenommen werden. So sollen zusammenhängende Bereiche identifiziert werden. Dabei ergeben sich allerdings auch Probleme, denn die Segmentierung gestaltet sich von Dokument zu Dokument unterschiedlich.

Des Weiteren muss darauf geachtet werden, die Passagen weder zu kleinteilig noch zu grob einzuteilen. Hier ist Fingerspitzengefühl erforderlich, um brauchbare Ergebnisse zu erhalten.
Weiter beschreibt Christian Kunz unterschiedliche Modelle, mit denen man die Relevanz von Passagen hinsichtlich bestimmter Suchphrasen bestimmen kann.
Passage Retrieval bietet einige Vorteile im Vergleich zum klassischen Dokumenten-Retrieval. Zum einen kann es die Arbeitsbelastung reduzieren, indem nur die relevantesten Textpassagen eines Dokuments herausgefiltert werden.
Zum anderen kann dieses Vorgehen eine Verbesserung der Precision- und Recall-Raten zur Folge haben, was mehr relevante Dokumente im Suchergebnis bedeutet. Die Voraussetzung für gute Ergebnisse ist allerdings eine genaue Vorbereitung sowie Erfahrung und umfangreiches Know-how. Außerdem ist zu bedenken, dass der Vorgang des Passage Retrievals sehr rechenintensiv sein kann und man entsprechende Ressourcen berücksichtigen sollte.
Wer mehr über die technischen Grundlagen von Suchmaschinen wissen möchte, kann auf seo-suedwest.de weiterlesen. Sehr empfehlenswert!
Wie misst Google Brand Authority?
Auf dem Moz Blog nimmt Simon Penson ein interessantes Google-Patent unter die Lupe, das er auch als „Panda-Patent“ bezeichnet. Kurz nach der Veröffentlichung des Patents folgte ein Video von Matt Cutts, in dem er beschrieb, wie Google Autorität und Popularität bewertet (wir berichteten). Das Video entfachte eine Diskussion darüber, wie Google populäre Seiten als solche erkennt, wenn sie nur selten verlinkt werden.

Google sieht sich an, nach welchen Begriffen ein Nutzer sucht und auf welche Ergebnisse er danach klickt, und stellt so eine semantische Referenz her. Dies hilft der Suchmaschine, eine Bewertung für Seiten durchzuführen.
Sollte dies das Panda-Patent sein, würden auch die Qualität einer Seite selbst sowie deren kommerzielle Ausrichtung mit einbezogen werden. Eine solche Entwicklung könnte die Art und Weise, wie Links gewertet werden und wie Relevanz bestimmt wird, stark verändern.
Wie wirkt sich das auf Links aus? Jeder Online Marketer weiß mittlerweile, dass es nicht mehr nur um follow-Links geht. Das ist nicht zuletzt auf deren inflationäre Nutzung zurückzuführen.
Das Patent könnte ein Indiz dafür sein, dass Google nofollow-Links mehr in das Ranking mit einbezieht als bisher gedacht: Betont werden die Wichtigkeit von „reference queries“ und „implied links“. Mit „implied links“ sind die Erwähnungen gemeint, die als Maß zur Berechnung von Autorität dienen.
Simon hat in England eigene Tests zu den folgenden Suchbegriffen durchgeführt:
- car insurance
- mortgage calculator
- mens clothing
Für diese konkurrenzstarken Begriffe gibt es meistens Brands, die an Position 1 in den SERPs ranken. Simon analysierte die ersten fünf „Top-Ranker“ hinsichtlich dem Anteil an follow-/nofollow-Links, der Anzahl an „brand mentions“ und dem Verhältnis von Links und Erwähnungen. Hier ein Beispiel für „car insurance“:

Ergebnis des Tests: Links sind immer noch wichtig, man sollte jedoch auch die Erwähnungen beachten und stärken. Gute Nachrichten gibt es möglicherweise auch für Betreiber kleiner Websites: Es scheint, als würde Google prüfen, wieviel vom Inhalt einer Seite relevant zu einer spezifischen Suchanfrage ist. Nischenseiten könnten so mehr Autorität bekommen.
Zum Schluss gibt uns Simon Penson noch ein paar Tipps: Seid glücklich über alle Erwähnungen und nofollow-Links und stärkt eure Marke. Der Schlüssel dazu sind kreative Kommunikationsstrategien und Inhalte, die gern verbreitet werden. Passend dazu gibt es von BuzzSumo auf Okdork eine Studie darüber, welche Inhalte sich besonders gut viral verbreiten. In diesem Sinne: Viel Spaß beim Testen und Ausprobieren  !
!
Schema.org – Googles Lesehilfe?
Welchen Nutzen eine semantische Auszeichnung von Web-Inhalten mit schema.org hat, erklärt Mario Schwertfeger bei catbirdseat. Google verändert seinen Suchalgorithmus immer mehr in Richtung der semantischen Spracherkennung, siehe Hummingbird-Update. Strukturiert man seine Webinhalte mit diesem Vokabular, erleichtert man so den Suchmaschinen das Erkennen der Inhalte.
Ein weiterer Vorteil sind die Rich Snippets: liegt eine inhaltliche Auszeichnung vor, kann Google zusätzliche Informationen für eine Seite in den SERPs anzeigen. Das kann die Klickrate erhöhen, denn diese Ergebnisse stechen visuell deutlich hervor. Der Screenshot zeigt ein Suchergebnis mit Rich Snippet zu der Anfrage „zubereitung grüner spargel“.
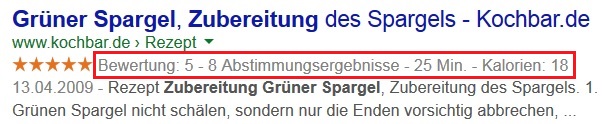
Auch hinsichtlich Voice Search und Conversational Search bietet schema.org Vorteile, denn eine genaue Bezeichnung der Seiteninhalte erleichtert Suchmaschinen die Darstellung auf unterschiedlichen Ausgabemedien. Um für die Zukunft der Suche gerüstet zu sein, empfiehlt es sich definitiv, über eine Implementierung nachzudenken.
Online Marketing News Worldwide
Russland hat eine neue Suchmaschine
Nachdem die Pläne für eine regierungsnahe Suchmaschine schon seit 2008 existieren, ist diese jetzt umgesetzt. Die neue russische Suchmaschine trägt den Namen „Sputnik“ und wird von der staatlich geführten Telekommunikationsfirma Rostelecom betrieben. Das Projekt hat bisher über 20 Mio. Dollar gekostet, ist jedoch essentiell für die russische Regierung als Kontrollorgan.

So bezeichnete Putin das Internet jüngst auf einer Konferenz in St. Petersburg als „CIA-Projekt“. Sputnik befindet sich gerade in der Testphase und wird in ein paar Wochen offiziell gelauncht. Bei einem Marktanteil von Yandex von über 60 % und von Google von über 20 % wird es Sputnik nicht einfach haben. Mit einem so mächtigen Partner im Rücken ist aber vieles möglich.
Vermischtes
- “Endorsed Tweets”: Auf onlinemarketingrockstars.de berichtet Roland Eisenbrand über das Geschäftsmodell, mit dem man Tweets von Prominenten kaufen kann. Ein Werbe-Tweet von Puff Daddy kostet ca. 30.000 $ und hat eine Reichweite von 9,6 Mio. Followern. Schnäppchen!
- Universal Analytics hat die Beta-Phase verlassen. Um euren Account auf die neue Version von Google Analytics umzustellen, startet ihr in der Property-Verwaltung Universal Analytics und wartet dann auf euren neuen Tracking-Code. Wer Sonderfunktionen wie Event-Tracking oder Remarketing in seinem Konto nutzt, sollte vorsichtig sein; denn alle mit Analytics interagierenden Code-Snippets müssen ebenfalls ausgetauscht werden. rankingCHECK verrät weitere Tipps zur reibungslosen Umstellung.
- Google+-Chef Vic Gundotra hat das Online-Netzwerk verlassen. Zahlreiche Quellen spekulierten nach dieser Nachricht darüber, ob Google Plus nun eingestampft wird oder ein neues Make-up bekommt. Angeblich soll sogar das gesamte Team aufgelöst und auf andere Abteilungen aufgeteilt werden. Was meint ihr, wie geht es weiter mit der Plattform?
- John Mueller von Google bestätigte, dass es kein Limit für ausgehende Links auf einzelnen Webseiten gibt. Somit beeinflusst die reine Anzahl von Links das Ranking in den SERPs nicht negativ. Google ist auch technisch in der Lage, eine größere Anzahl von ausgehenden Links zu verarbeiten. Anders sieht es aus, wenn es sich um schlechte Links handelt. Dies kann nach wie vor schädlich für das Ranking sein.
- Auf konversionskraft schreibt Ronald Grimminger darüber, wie man Werbemaßnahmen besser personalisieren kann und dadurch mehr qualifizierten Traffic erhält. Dort erfahrt ihr auch, welche Folgen schlechte Personalisierung nach sich ziehen kann.
- Neue Features im Keyword Planner Tool: Googles Keyword Planer wurde aufgerüstet und hat gleich mehrere neue Eigenschaften bekommen. Searchengineland zählt auf, was die wichtigsten Neuheiten sind. Es gibt visuelle Darstellungsmöglichkeiten für geografische Schätzungen von Such- oder Klickvolumina, denen man selbstgewählte Zielregionen und Zeiträume hinzufügen kann. Die Darstellungen lassen sich außerdem nach Endgerät aufsplitten.
Veranstaltungen
Vom 5. bis 7. Mai findet in Berlin die iico statt. Dort dreht sich alles um die digitale Unternehmenskommunikation und wie diese im Web 2.0 umgesetzt werden kann. Die Themen reichen von Big Data über Content Marketing bis hin zu User Experience Management.

Auf der re:publica wird vom 6. bis 8. Mai unter dem Motto „Into the Wild“ über neue Wege der Netzfreiheit diskutiert und wie man diese schützen kann. Die Social-Media-Konferenz bezieht dabei Impulse aus Politik, Wirtschaft und Wissenschaft mit ein und bietet ein spannendes Programm.
Wir wünschen euch ein schönes Wochenende, bis nächste Woche!
Sabine und die SEO Trainees





3 Antworten
Viele interessante Dinge habe ich bei dir wieder gelernt. Letztens hatte ich tatsächlich den Fall, dass Google bei mir immer den Titel umgeschrieben hat. Dachte eher daran, dass mein SEO Plugin nach etlichen Updates daran Schuld gewesen war. Falsch gedacht
Bei dem Fall, dass Google selbst den Titel bestimmt, gehe ich in Zukunft so vor, dass ich Googles Titel so modifiziere, so dass die wichtigsten Merkmale weiter enthalten bleiben.